
For our Taskmaster Posts 1 2 3 and 4 we had a really good look at Pyspark using an online dataset. but abandoned it when we realised that the data wasn’t quite as we wanted it and some data sets were missing.
Parts 5 and 6 we got a new data set and created a transform layer and dimensions. Now its time to finally create the fact table
Lets create a new Notebook – Taskmaster Fact V2

Date Keys
Our Date Keys will be integer. if we take a quick look at our Delta PARQUET file
df = spark.sql("SELECT * FROM DebbiesFabricLakehouse.dimdate LIMIT 1000")
display(df)
Out date key is in the following Int Format 20240416
We want the Episode date Key to follow this trend.
At transformation level we created Year month and Day. We just need to merge these to create the date
Merge Date Key
from pyspark.sql.functions import col, concat_ws, expr
dftm = dftm.withColumn("DateKey", concat_ws("", col("year"), col("month"), col("day")).cast("int"))
display(dftm)
Bring through the Episode Key
Now we want to add the Delta PARQUET table to a dataframe. So we can add the key to the dataframe. Then we can create another dataframe with all the keys and the points metric to make the fact table.
dfep = spark.sql("SELECT * FROM DebbiesFabricLakehouse.dimepisode")
display(dfep)# Add Episode Key to the df
dftm = dftm.join(dfep, (dftm["Series"] == dfep["Series"]) & (dftm["Episode Name"] == dfep["EpisodeName"]), "left_outer")\
.drop(dfep.Series).drop(dfep.EpisodeNo).drop(dfep.EpisodeName)
# The resulting DataFrame 'joined_df' contains all rows from dftask and matching rows from dfob
display(dftm)
And set any null values to -1. Our default not known
dftm = dftm.fillna(-1, subset=[‘EpisodeKey’])
Bring through the Task Key
We can repeat the above to bring in the Task Key
dft = spark.sql("SELECT * FROM DebbiesFabricLakehouse.dimtask")
display(dft)# Add Task Key to the df
dftm = dftm.join(dft, (dftm["Task"] == dft["Task"]), "left_outer")\
.drop(dft.Task).drop(dft.TaskType).drop(dft.Assignment).drop(dft.TaskOrder)
# The resulting DataFrame 'joined_df' contains all rows from dftask and matching rows from dfob
display(dftm)dftm = dftm.fillna(-1, subset=['TaskKey'])Bring in Contestant Key
dfc = spark.sql("SELECT * FROM DebbiesFabricLakehouse.dimtask")
display(dfc)# Add Contestant Key to the df
dftm = dftm.join(dfc, (dftm["Contestant"] == dfc["ContestantName"]), "left_outer")\
.drop(dfc.ContestantID).drop(dfc.ContestantName).drop(dfc.Team).drop(dfc.Image).drop(dfc.From).drop(dfc.Area).drop(dfc.Country).drop(dfc.Seat).drop(dfc.Gender)\
.drop(dfc.Hand).drop(dfc.Age).drop(dfc.AgeRange)
# The resulting DataFrame 'joined_df' contains all rows from dftask and matching rows from dfob
display(dftm)dftm = dftm.fillna(-1, subset=['ContestantKey'])And now we have all of our keys

Partitioning
We want to Partition the fact table by Series date, However, We only have the individual task information.
Lets see if we can add another date Key for Series.
MIN and Group Episode date by Series
from pyspark.sql.functions import min, substring
# Group by "Contestant" and aggregate the minimum "Episode Date"
dfminSeries= dftm.groupBy("Series").agg(min("Episode Date").alias("min_episode_date"))
#And create year month and day and set as a Key
dfminSeries = dfminSeries.withColumn("Year", col("min_episode_date").substr(1, 4))
dfminSeries = dfminSeries.withColumn("month", col("min_episode_date").substr(6, 2))
dfminSeries = dfminSeries.withColumn("day", substring(col("min_episode_date"), 9, 2))
dfminSeries = dfminSeries.withColumn("SeriesStartDateKey", concat_ws("", col("year"), col("month"), col("day")).cast("int"))
# Show the resulting DataFrame
dfminSeries.show()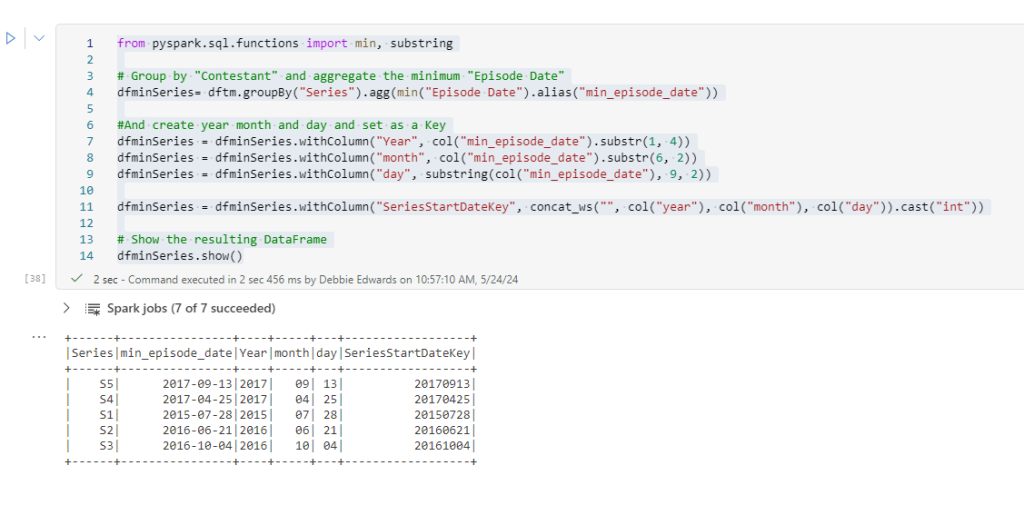
Merge the New Key into the main dataframe
# Add SeriesStartDateKey Key to the df
dftm = dftm.join(dfminSeries, (dftm["Series"] == dfminSeries["Series"]), "left_outer")\
.drop(dfminSeries.Series).drop(dfminSeries.min_episode_date).drop(dfminSeries.Year).drop(dfminSeries.month).drop(dfminSeries.day)
# The resulting DataFrame 'joined_df' contains all rows from dftask and matching rows from dfob
display(dftm)
Create the Fact table
dftmfact = dftm.select(
col("EpisodeKey"),
col("TaskKey"),
col("ContestantKey"),
col("SeriesStartDateKey"),
col("DateKey").alias("EpisodeDateKey"),
col("Points").cast("integer"),
col("Winner").cast("integer")
)
dftmfact.show()

This can now be saved to our Delta PARQUET and PARQUET so we have our full set of data to create the star schema.
Delta PARQUET Partitioned.
We now want to Partition our fact table by the SeriesStartDateKey
from delta.tables import DeltaTable
dftmfact.write.mode("overwrite").option("overwriteSchema", "true")\
.partitionBy("SeriesStartDateKey").format("delta").saveAsTable("factTaskmaster")So Why partition?
Partitioning the Parquet table gives you specific benefits
If we were to just look at one series. The execution engine can identify the partition and only read that partition. it significantly reduces the data scanned.
Faster query performance.
Delta Lake will automatically create the partitions for you when you append data, simplifying data management.
Partitioning is really useful for large datasets. Allowing you to skip partitions.
Lets see what this actually looks like once run.


At this level it looks no different to the unpartitioned Delta PARQUET File.
If we go to the Workspace

Click on the Semantic Model

Then the Lakehouse
You can right click and View the underlying files.
Lets have a look at another way of doing this.
One Lake File Explorer
Its time to download the One Lake File Explorer which is a new app available with Fabric.
https://www.microsoft.com/en-us/download/details.aspx?id=105222



We can now see the One Lake in our File Explorer just like you can in One Drive, And you also get a local copy.
Lets have a look at the Taskmaster Partitioned Delta Table against a None Partitioned Table
None Partitioned
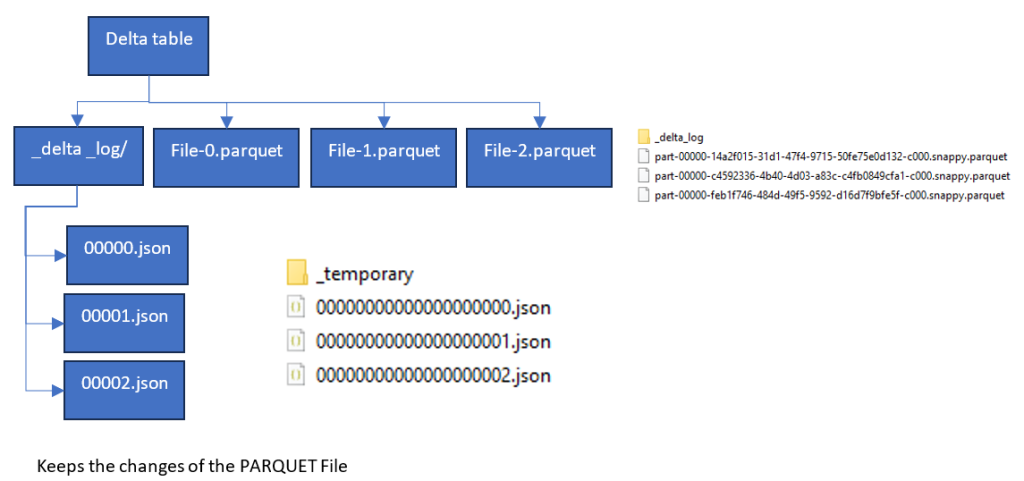
Partitioned

We have 3 parts at 4 kb each for this partition. What is the recommended size?
64 mb to 1 gb is around the file size we want achieve. Our file sizes are small because there isn’t much data at the moment.
So we have 3 change files in the delta log which correspond to the 3 PARQUET Files. the Delta log lets Fabric know which file to go with when we are looking at our data.
So what do we do when we want to clean up old files?
Maintenance – Optimize and VACUUM


We can optimize our file sizes and also Vacuum old data outside of our retention threshold.
Creating the PARQUET Table.
Now its time to create the PARQUET table that is not delta. This is only happening to test functionality between the two.
In a previous post we learned that you couldn’t partition a PARQUET table. You need to update to Delta to do this,
dftmfact.write.mode("overwrite").parquet('Files/Data/Silver/factTaskmaster.parquet')Conclusion
Its important to note that Delta PARQUET and PARQET have the same PARQUET files.
Delta just creates the extra delta log tables to hold the changes. The PARQUET is a columnar storage solution, in the same way as the power BI Columnar data store.
So we now have our gold layer of Facts and Dimensions. Both as PARQUET( unmanaged) and Delta PARQUET (Managed)
In the next post we will see what we can do with these files.
