After 14 years using Microsoft On Premise BI Tools (SQL Server, Reporting Services, Integration Services and Analysis Services) Its time to embrace Business Intelligence in the cloud.
In parts 1 and 2 we created and updated DimContestant
In Part 3 we created DimTask, DimEpisode and DimDate
Its time to create the fact table. the first thing we need to do is to get an understanding of what Facts we have and how they would join to the data we have created in the dims so far.
#Read the first file into a dataframe
dfattempts = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/attempts.csv")
# dfattempts now is a Spark DataFrame containing CSV data from "Files/Data/Bronze/attempts.csv".
display(dfattempts)
Contains points and ranks and appears to be at the episode and contestant level
episode_scores
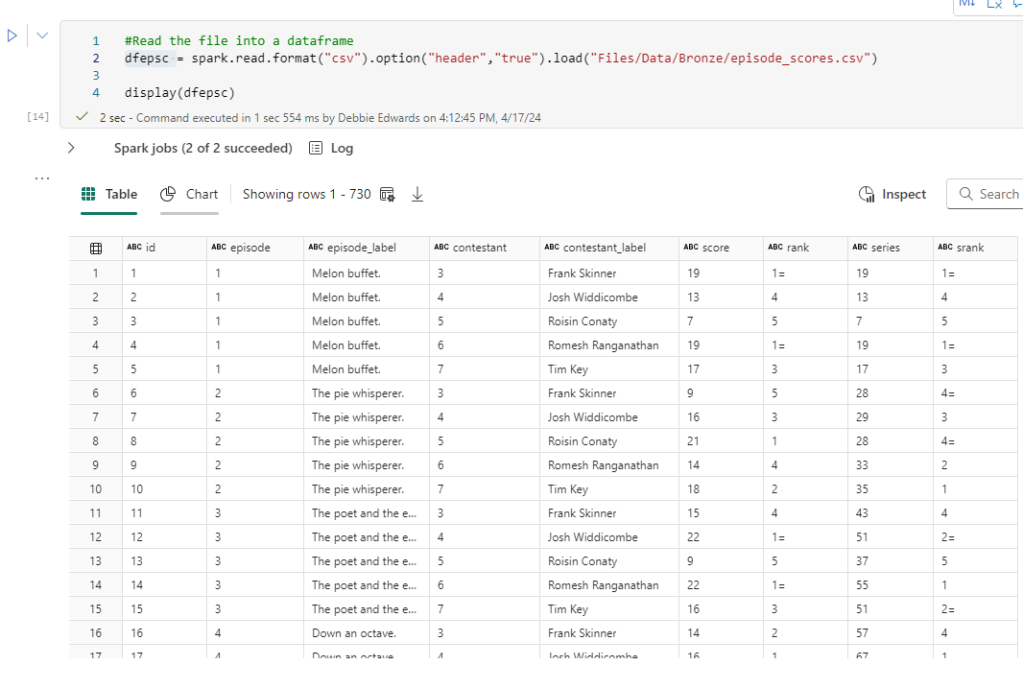
#Read the file into a dataframe
dfepsc = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/episode_scores.csv")
display(dfepsc)
episode_scores is new to this project but seems a really good data set. Holds scores and Ranks at the episode and contestant level (but not at task level)
we actually don’t need this because its just aggregated data. We can remove this from our transformations. Power BI will aggregate for us
episodes
#Read the file into a dataframe
dfepis = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/episodes (1).csv")
display(dfepis)
This contains Dates and points. However the Scores are at Episode Level. We will be able to get this information from DAX, summing the individual Scores so we don’t need the scores at all. All we are interested in is the air date.
the number of columns vary. We need to make sense of what we have
Create the data we need from attempts
# Select multiple columns with aliases
dfdfattemptsf = dfattempts.select(
dfattempts.task.alias('attTaskID'), #Join to DimTask
dfattempts.task_label.alias('attTask'),
dfattempts.episode.alias('attEpisode'),
dfattempts.series.alias('attSeries'),
dfattempts.contestant_label.alias('attContestant'), #Join to DimContestant
dfattempts.points.alias('attPoints')
).distinct()
# Show the resulting DataFrame
display(dfdfattemptsf)
The Points in Attempts are the best ones we have at the moment because the Task csv was empty.
we are clearly now hitting real data problems and in a normal project we would be going back to the team creating the data to get them to resolve the problems.
Filter attempts
the attempts is our main table but we could do with the episode and Series information working with our dimensions we have and we only have Ids for both
Are episode and series related with the correct IDs? Lets do some filter queries to look at series 1, episode 1.
After a few filtered queries, there is clearly a some data issues, or unknowns that I am not aware of. With attempts. The episode 1 and series 1 doesn’t match the contestants and tasks (I know because I watched it).
For episodes (1) (Above) we do have the correct information for episode and series. But we aren’t using these to get data.
More problems with Episode Scores. Episode appears to be correct. But the series ID is completely different so we cant match on this. But we aren’t using this data any more.
We need to look at our PARQUET file DImEpisode
The first thing we need to do is Load our DimContestant PARQUET data back into a dataframe and to to this, we have to update the code slightly as previously we have loaded in csv files.
# Read Parquet file using read.parquet()
dfdimep = spark.read.parquet("Files/Data/Silver/DimEpisode.parquet")
display(dfdimep)
To Get the path, Click on you File in the Files Folder in the Lakehouse and Copy ABFS Path, Copy Relative path for spark gives you a more concise path
We are now using the silver layer of the medallion architecture in the path. All our bronze landing data has been transformed.
Are our IDs correct in the Dim for Attempts, or for the Tasks by Objective csv?
Now we have a real issue. Our Episodes cant join to attempts.
Join with one Condition
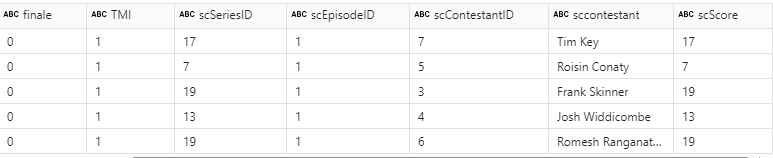
We can join episode Scores to Episode first via the episode name? This would be an issue if you have repeating episode names in Series, but we are lucky that this is not the case.
# condition
original_condition = dfepis["title"] == dfepscf["scEpisode"]
# Now perform the left outer join
dfEpScorej = dfepis.join(dfepscf, on=original_condition, how="full").drop(dfepscf.scEpisode)
display(dfEpScorej)
Filter new transformed table for episode 1 series 1
import pyspark.sql.functions as F
filtered_df = dfEpScorej.filter((F.col('episode') == 1) & (F.col('series') ==1))
display(filtered_df)
Filtering on Task 1 Season 1 gives us all 5 contestants against the episode. There are lots of columns we can remove. For example, we don’t need to hard code the winner. This can be done via Power BI DAX. So, the above join will be slightly updated with .drop.
# condition
original_condition = dfepis["title"] == dfepscf["scEpisode"]
# Now perform the left outer join
dfEpScorej = dfepis.join(dfepscf, on=original_condition, how="full").drop(dfepscf.scEpisode)\
.drop(dfepscf.scEpisodeID).drop(dfepis.winner).drop(dfepis.winner_label).drop(dfepis.studio_date).drop(dfepis.winner).drop(dfepis.finale).drop(dfepis.TMI)
display(dfEpScorej)
Full is being used as the join because we want each side even if they haven't been joined.
Use dfEpScorej now instead of dfepis and dfepscf
We have the attempts (dfattemptsf) left
So how can we join this final table?
We can’t join by Task because Episodes doesn’t include task
We can’t join by Series because the Series IDs don’t match and neither does Episode.
We can match by Contestant but Contestants can take part in multiple series so the join doesnt work
As it stands we cant actually match in this table so we need to go with Episodes and Scores for the fact table.
Add the Dimension Keys into the transformed table
Join DimContestants Via Contestant Name
We Can’t use ID but we can use name.
Also when we join we only want the Key and we can immediately remove everything relating to Contestant.
# Original condition
original_condition = dfdimcont["contestant"] == dfEpScorej["sccontestant"]
# Adding another condition based on the 'name' column
#combined_condition = original_condition & (dfdimcont["contestant"] == dfEpScorej["sccontestant"])
# Now perform the left outer join
dfEpScorej = dfEpScorej.join(dfdimcont, on=original_condition, how="left")\
.drop(dfdimcont.TeamName).drop(dfdimcont.teamID).drop(dfdimcont.age).drop(dfdimcont.gender)\
.drop(dfdimcont.hand).drop(dfdimcont.ageRange).drop(dfdimcont.dob)\
.drop(dfdimcont.contestant).drop(dfdimcont.contestantID)\
.drop(dfEpScorej.sccontestant).drop(dfEpScorej.scContestantID)
display(dfEpScorej)
If we have any null values they can be replaced with -1
All is good. we can join it into the transformed table. Removing everything but the key using .drop
the data was checked that it was ok before adding all the .drop’s into the code,
# Original condition
original_condition = dfdimep["seriesID"] == dfEpScorej["series"]
# Adding another condition based on the 'name' column
combined_condition = original_condition & (dfdimep["episodeID"] == dfEpScorej["episode"])
# Now perform the left outer join
df = dfEpScorej.join(dfdimep, on=combined_condition, how="left")\
.drop(dfdimep.episodeTitle).drop(dfdimep.episodeID).drop(dfdimep.series).drop(dfdimep.seriesID)\
.drop(dfEpScorej.series_label).drop(dfEpScorej.series).drop(dfEpScorej.episode).drop(dfEpScorej.title)
display(df)
This specific project has been abandoned because the data doesn’t give me what I need join wise to create the star schema. Mostly because there is clearly a main table with missing data.
But, I can’t wait to take what I have learned and try again with another data set.
Parts 1 to 4 have given me some great insight into analysis transforming and modelling with Pyspark.
In Parts 1 and 2, we did a lot of analysis on the data. Understood Contestants and the data between the csv files attempts and people. Its now time to create some of the other dimensions we need for the project.
DimTasks
DimEpisodes
DimDate
Back to our Taskmaster Notebook to see what other data is available to use. But first of all. When creating stored procedures to transform data on SQL DB, The stored procedures are usually split into Dims and Facts. Its time to split this notebook up into the corresponding dims and facts.
Dim Contestants
A copy of the original file is saved as DimContestants. Then the new notebook is opened and everything Customer related is saved, including the initial configuring of the Lakehouse.
The notebook ends with the creation of the overwritten files.
The Code
spark.stop()
Is more interesting. Do we want to stop Spark after every dimension and fact creation. Or only at the end of the process?
One to think about but for this, lets have this after every notebook has run.
DimEpisode
Another copy is made to create DimEpisode. everything is removed apart from code that can relate to DimEpisode.
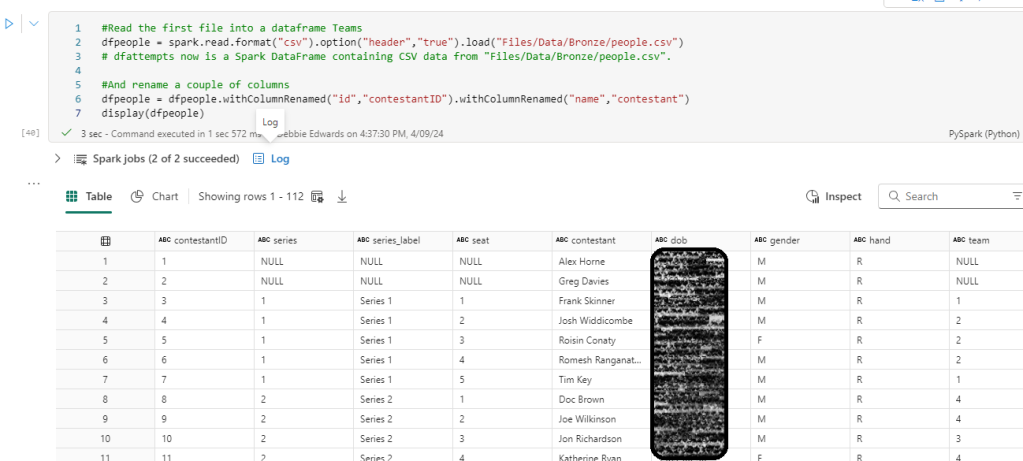
#Read the first file into a dataframe Teams
dfep = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/episodes (1).csv")
# dfattempts now is a Spark DataFrame containing CSV data from "Files/Data/Bronze/episodes (1).csv".
#And rename a couple of columns
#dfpeopletransf = dfpeople.withColumnRenamed("id","contestantID").withColumnRenamed("name","contestant")
display(dfep.distinct())
We have some key information like dates in here but we will save these as keys for the fact table when we get to the fact table.
There is also a really important fact in here. Points.
Create Seriesand Episodes
# Select multiple columns with aliases
dfepisode = dfep.select(
dfep.series.alias('seriesID'),
dfep.series_label.alias('series'),
dfep.episode.alias('episodeID'),
dfep.title.alias('episodeTitle')
).distinct()
# Show the resulting DataFrame
display(dfepisode)
Check that we have distinct Episodes
#Lets immediately do the group by and min value now we know what we are doing to create a distinct list (Removing any IDs for a different series)
#import the function col to use.
from pyspark.sql.functions import col
from pyspark.sql.functions import count as _count
#Creates the full distinct list.
dfepisode.groupBy('Series', 'episodeID', 'episodeTitle' )\
.agg(_count('episodeTitle').alias('TotalRecords'))\
.filter(col('TotalRecords')>1).show(1000)
This looks good. We just need to add a default row and a key and we have ourselves another dimension which will eventually contain a hierarchy between series and episode.
Add default row for seriesand episode
we are now doing the same code blocks we created for Contestants.
from pyspark.sql import SparkSession
from pyspark.sql import Row
# Create a sample DataFrame
data = [(-1, "Not Known","-1","Not Known")]
columns = ["seriesID", "series", "episodeID", "episodeTitle"]
new_row = spark.createDataFrame(data, columns)
# Union the new row with the existing DataFrame
dfepisode = dfepisode.union(new_row)
# Show the updated DataFrame
dfepisode.show(1000)
#Just in case. We distinct again to remove any extra NA Rows
dfepisode = dfepisode.distinct()
dfepisode.show(1000)
Create the Episode Key
#Create an Episode Key
# Imports Window and row_number
from pyspark.sql import Window
from pyspark.sql.functions import row_number
# Applying partitionBy() and orderBy()
window_spec = Window.partitionBy().orderBy("episodeID")
# Add a new column "row_number" using row_number() over the specified window
dfepisode = dfepisode.withColumn("EpisodeKey", row_number().over(window_spec)- 2)
# Show the result
dfepisode.show(1000)
Create Delta PARQUET
What is the difference between Delta PARQUET and PARQUET
The Basic PARQUET File is the same, but we also have a _delta_log directory and checkpoint files. The Delta is simply a folder that contains these objects.
from delta.tables import DeltaTable
dfepisode.write.mode("overwrite").option("overwriteSchema", "true").format("delta").saveAsTable("dimEpisode")
We have re worked the code so we overwrite the schema also if it has changed to avoid errors
Create PARQUET
#Read the first file into a dataframe Teams
dftasks = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/tasks_by_objective.csv")
display(dftasks.distinct())
DimTask
Save a copy again and create DimTask
The Notebooks can be easily selected from the left hand pane and are automatically saved.
And in the workspace we can see that we have three new files to add
Our Last dimension before adding a dim date table will be tasks. After loading the tasks csv, it appears to be empty which is odd because it says there should be over 809 rows so something does appear to have gone wrong with the data source.
We need to look around the files and see what we can get.
We already know that the attempts contains tasks but doesn’t have as much data in it.
Getting Tasks from Attempts
#Read the first file into a dataframe
dfattempts = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/attempts.csv")
# dfattempts now is a Spark DataFrame containing CSV data from "Files/Data/Bronze/attempts.csv".
display(dfattempts)
attempts is read into this notebook as a DataFrame again because there is a task column in this table.
# Select multiple columns with aliases
dftaskat = dfattempts.select(
dfattempts.task.alias('taskID'),
dfattempts.task_label.alias('task_label')
).distinct()
# Show the resulting DataFrame
display(dftaskat)
There are 264 tasks in Task objective that aren’t in attempts
#How many match?
filtered_df = dftaskcheck.filter((dftaskcheck['task'] == dftaskcheck['taskOb']))
filtered_df.show(1000)
rows = filtered_df.count()
print(f"DataFrame Rows count where ID and Task ID are identical: {rows}")
157 tasks are in both task objective and attempts. Lets now try to get a full list.
COALESCE and REPLACE
# We are going to COALESCE to get the item that isnt null into a null field
from pyspark.sql.functions import coalesce
from pyspark.sql import functions as F
dftaskcheck = dftaskcheck.withColumn("newTaskID",coalesce(dftaskcheck.taskID,dftaskcheck.id))
dftaskcheck = dftaskcheck.withColumn("newTask",coalesce(dftaskcheck.task,dftaskcheck.taskOb))
#dftaskcheck= dftaskcheck.select(col("newTaskID").alias("taskID"), col("newtask").alias("task"),
#col("objective").alias("objectiveID"),col("objective_label").alias("objective")).distinct()
dftask = dftaskcheck.select(
dftaskcheck.newTaskID.alias('taskID'),
dftaskcheck.newTask.alias('task'),
dftaskcheck.objective_label.alias('objective'),
).distinct()
# Get Rid of ▲ and ▼
dftask = dftask.withColumn("objective", F.regexp_replace("objective", "▲", ""))
dftask = dftask.withColumn("objective", F.regexp_replace("objective", "▼", ""))
display(dftask)
So here coalesce has been used to return the DataFrame with a new column that gives us the none null item.
Then to finish ▲ and ▼ are removed.
We now just need to clean up the null objectives. Lets just assume the null objectives are points.
fillna() deals with missing values. It allows you to replace or fill in null values with specified values
Create default NA Row
We have done this code multiple times now so the blog post will just show the code and not screenshots
from pyspark.sql import SparkSession
from pyspark.sql import Row
# Create a sample DataFrame
data = [(-1, "Not Known","Not Known")]
columns = ["taskID", "task", "objective"]
new_row = spark.createDataFrame(data, columns)
# Union the new row with the existing DataFrame
dftask = dftask.union(new_row)
# Show the updated DataFrame
dftask.show(1000)
Running a DISTINCT just in case we applied the above more than once.
#Just in case. We distinct again to remove any extra NA Rows
dftask = dftask.distinct()
dftask.show(1000)
Creating the Contestant Key
# Imports Window and row_number
from pyspark.sql import Window
from pyspark.sql.functions import row_number
# Applying partitionBy() and orderBy()
window_spec = Window.partitionBy().orderBy("taskID")
# Add a new column "row_number" using row_number() over the specified window
dftask = dftask.withColumn("taskKey", row_number().over(window_spec)- 2)
# Show the result
dftask.show(1000)
Create DELTA PARQUET TABLE
from delta.tables import DeltaTable
dftask.write.mode("overwrite").format("delta").saveAsTable("dimTask")
Remember, In the context of the Lakehouse the tables created in the Files folder are external tables.
You don’t see external table in semantic model or SQL endpoint so when we get further with this exercise it will be interesting to see what we can do with both PARQUET files.
This is the end of the Task Notebook.
Dim Date
We have dates in our data which means, for a STAR schema we need a Date dimension and yes, We can create this in a Notebook.
Create a new notebook Dim Date
Start of again by configuring the Lakehouse and starting the spark session
There are many ways to do this. You could use SQL Magic, Or embed SQL into the Pyspark code. You could create it via a dataflow and send the result to the Lakehouse. This exercise is all about trying to do everything using PySpark Code.
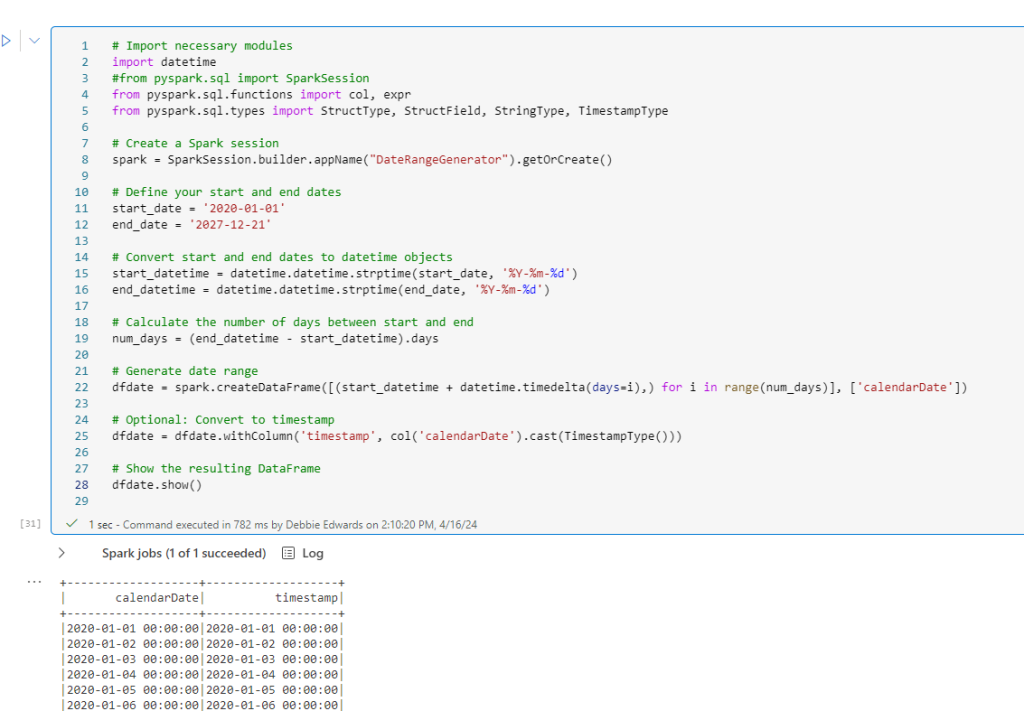
# Import necessary modules
import datetime
#from pyspark.sql import SparkSession
from pyspark.sql.functions import col, expr
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
# Create a Spark session
spark = SparkSession.builder.appName("DateRangeGenerator").getOrCreate()
# Define your start and end dates
start_date = '2020-01-01'
end_date = '2027-12-21'
# Convert start and end dates to datetime objects
start_datetime = datetime.datetime.strptime(start_date, '%Y-%m-%d')
end_datetime = datetime.datetime.strptime(end_date, '%Y-%m-%d')
# Calculate the number of days between start and end
num_days = (end_datetime - start_datetime).days
# Generate date range
dfdate = spark.createDataFrame([(start_datetime + datetime.timedelta(days=i),) for i in range(num_days)], ['calendarDate'])
# Optional: Convert to timestamp
dfdate = dfdate.withColumn('timestamp', col('calendarDate').cast(TimestampType()))
# Show the resulting DataFrame
dfdate.show()
Lets look at this in more detail:
We import the necessary modules:
import datetime datetime function is used to work with this format.
from pyspark.sql import SparkSession These are the entry points for working with Data Frames. ( I don’t think we need this because a Spark session is already running).
from pyspark.sql.functions import col, expr.
col is a function and allows you to reference a column in a DataFrame by its name. E.g. col(“Column_Name”)
expr is a function that allows you to execute SQL Like expressions with Pyspark.
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
StructType is used to define a schema and represents a collection of fields.
StructField are these fields in the StructType. And the fields in question are strings and timestamps
And now into the main Code block
The Start_date and End_dates are defined and can be changed when necessary
Both dates are converted into datetime format Year Month and Day
Next we get the number of dates between start and end in .days
Then the date_df is generated.
range(num_days)
Generates a sequence of integers from 0. Each of these integers represents the number of dates from the start date.
[(start_datetime + timedelta(days=i),) for i in range(num_days)]:
This creates a list of tuples (Tuples are used to store multiple items in a single variable) so if there is a week of days, i would be 7 and we would have 7 rows of dates.
Finally we create another column which has been converted to timestamp. Which we will use moving forward.
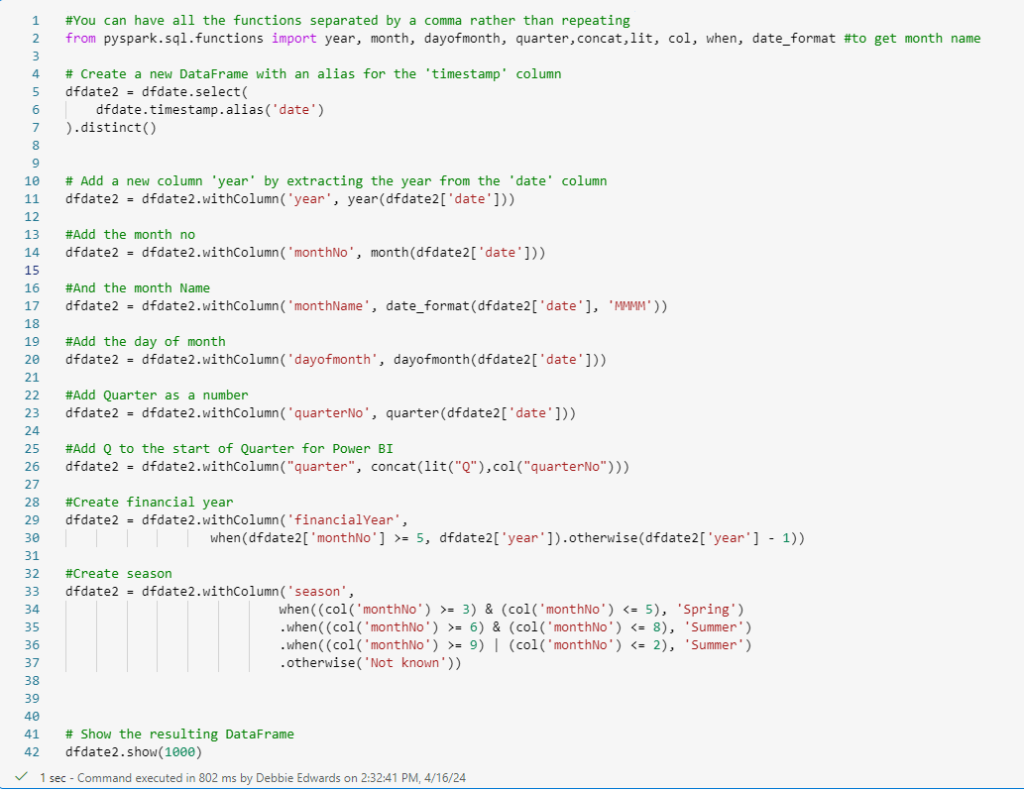
Add Columns to DimDate
We are now going to set a range of columns up for Date
#You can have all the functions separated by a comma rather than repeating
from pyspark.sql.functions import year, month, dayofmonth, quarter,concat,lit, col, when, date_format #to get month name
# Create a new DataFrame with an alias for the 'timestamp' column
dfdate2 = dfdate.select(
dfdate.timestamp.alias('date')
).distinct()
# Add a new column 'year' by extracting the year from the 'date' column
dfdate2 = dfdate2.withColumn('year', year(dfdate2['date']))
#Add the month no
dfdate2 = dfdate2.withColumn('monthNo', month(dfdate2['date']))
#And the month Name
dfdate2 = dfdate2.withColumn('monthName', date_format(dfdate2['date'], 'MMMM'))
#Add the day of month
dfdate2 = dfdate2.withColumn('dayofmonth', dayofmonth(dfdate2['date']))
#Add Quarter as a number
dfdate2 = dfdate2.withColumn('quarterNo', quarter(dfdate2['date']))
#Add Q to the start of Quarter for Power BI
dfdate2 = dfdate2.withColumn("quarter", concat(lit("Q"),col("quarterNo")))
#Create financial year
dfdate2 = dfdate2.withColumn('financialYear',
when(dfdate2['monthNo'] >= 5, dfdate2['year']).otherwise(dfdate2['year'] - 1))
#Create season
dfdate2 = dfdate2.withColumn('season',
when((col('monthNo') >= 3) & (col('monthNo') <= 5), 'Spring')
.when((col('monthNo') >= 6) & (col('monthNo') <= 8), 'Summer')
.when((col('monthNo') >= 9) | (col('monthNo') <= 2), 'Summer')
.otherwise('Not known'))
# Show the resulting DataFrame
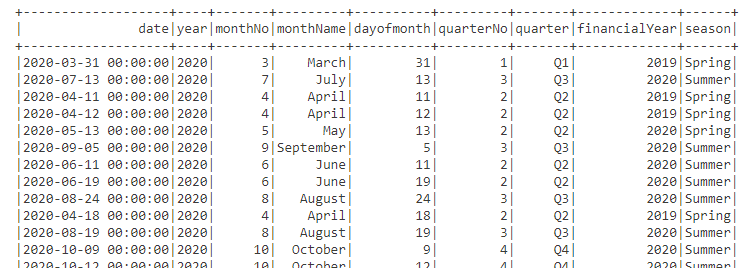
dfdate2.show(1000)
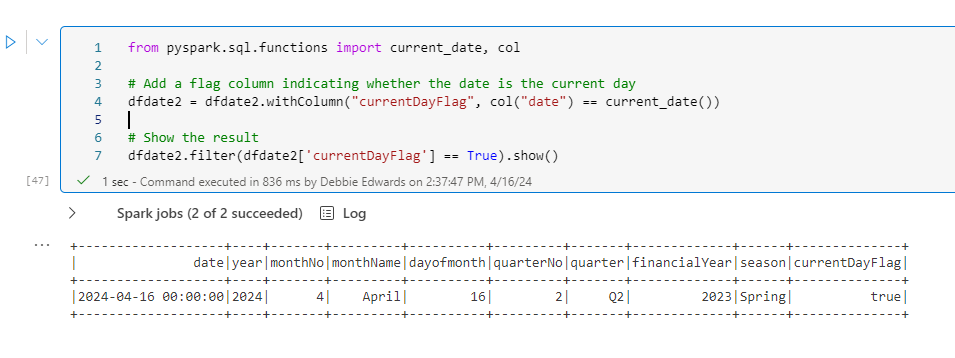
Create a current Day Flag
its always useful to have some date flags to use in Analysis
from pyspark.sql.functions import current_date, col
# Add a flag column indicating whether the date is the current day
dfdate2 = dfdate2.withColumn("currentDayFlag", col("date") == current_date())
# Show the result
dfdate2.filter(dfdate2['currentDayFlag'] == True).show()
Note that we can now quickly look at the current date (this would need to be updated every day)
Create a current month Flag
from pyspark.sql.functions import month, current_date
dfdate2 = dfdate2.withColumn("currentMonthFlag", month(dfdate2['date']) == month(current_date()))
# Show the result
dfdate2.filter(dfdate2['currentMonthFlag'] == True).show()
Create a current year Flag
from pyspark.sql.functions import year, current_date
dfdate2 = dfdate2.withColumn("currentYearFlag", year(dfdate2['date']) == year(current_date()))
# Show the result
dfdate2.filter(dfdate2['currentYearFlag'] == True).show()
Create the Date Key
For this we need Year, Month and Day to create an integer key which will be recreated in the fact table
from pyspark.sql.functions import concat_ws, lpad, col
# Assuming you have a DataFrame named 'df' with columns 'year', 'month', and 'day'
dfdate2 = dfdate2.withColumn('DateKey',
concat_ws('', col('year'),
lpad(col('monthNo'), 2, '0'),
lpad(col('dayOfMonth'), 2, '0')).cast('int'))
dfdate2.show()
lpad is used to left pad a string column
concat_ws is used to concatename string columns into a single column
Save as Delta PARQUET and PARQUET
from delta.tables import DeltaTable
dfdate2.write.mode("overwrite").format("delta").saveAsTable("dimDate")
In Part 1, a Contestants Dimension was created from the csv file attempts csv. The data from this was transformed and added into a PARQUET file and a DELTA PARQUET file so we can test the differences later.
There are more csv files to look at and one specifically gives us more details for the Contestants dim
people.csv
The task here is to go back to the original Notebook and see if we can add this new information
The first bit of code to create goes after the following blocks of code.
Starting Spark Session
Reading attempts.csv into a dataframe
Renaming columns and creating dfattempttrans
creating the distinct dfcont from dtattempts (Creating the Contestants Dim)
#Read the first file into a dataframe Teams
dfpeople = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/people.csv")
# dfattempts now is a Spark DataFrame containing CSV data from "Files/Data/Bronze/people.csv".
#And rename a couple of columns
dfpeople = dfpeople.withColumnRenamed("id","contestantID").withColumnRenamed("name","contestant")
display(dfpeople)
We have used .withColumnRenamed to change a couple of columns.
ID to ContestantID and name to contestant
Before moving on. the assumption is that People is a distinct list.
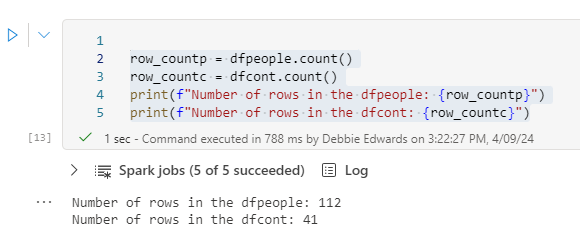
Lets count the rows in each table so far
row_countp = dfpeople.count()
row_countc = dfcont.count()
print(f"Number of rows in the dfpeople: {row_countp}")
print(f"Number of rows in the dfcont: {row_countc}")
There is a lot more people in our new DataFrame. But are they unique?
#We need to test. Do we have unique Contestants?
#We need to import a function for col
from pyspark.sql.functions import *
dfpeople.groupBy('contestant')\
.agg(min('contestantID').alias('MinContestantID'),count('contestant').alias('TotalRecords'))\
.filter(col('TotalRecords')>1).show(1000)
Using \ allows us to break the code onto separate lines
We have the same issue here where some of the people have more than one record so lets filter a few
The original assumption in Part 1 was incorrect. We have multiple based on the Champion of Champion series here. So the ID is not for the contestant. it’s for the contestant and series and some people have been on multiple series.
Yes. So we need to rethink dim contestants. Actually if they exist in both we only need to use people. So we need to join them and check out if this is the case
Checking values exist in People that we can see in attempts – rename Columns
We want to join the contestants that we obtained the attempts table to dfpeople. Simply so we can check what is missing?
We know we have more in people. But what happens if there are values missing in people than are in attempts? This will cause us more problems.
We will join on the ID and the contestant so before the join. Lets rename the dfCont columns so we don’t end up with duplicate column names
#And rename a couple of columns
dfcont = dfcont.withColumnRenamed("contestantID","cont_contestantID").withColumnRenamed("contestant","cont_contestant")
display(dfcont)
join dfCont and dfPeople
Please note that when joining tables, its better to create a new DataFrame rather than update an original one, because if you have to run it again, the DataFrame you join from will have changed.
# Original condition
original_condition = dfpeople["contestantID"] == dfcont["cont_contestantID"]
# Adding another condition based on the 'name' column
combined_condition = original_condition & (dfpeople["contestant"] == dfcont["cont_contestant"])
# Now perform the left outer join
dfcontcheck = dfpeople.join(dfcont, on=combined_condition, how="full")
display(dfcontcheck)
So we have everything in one table. Lets do some filtering to check our findings
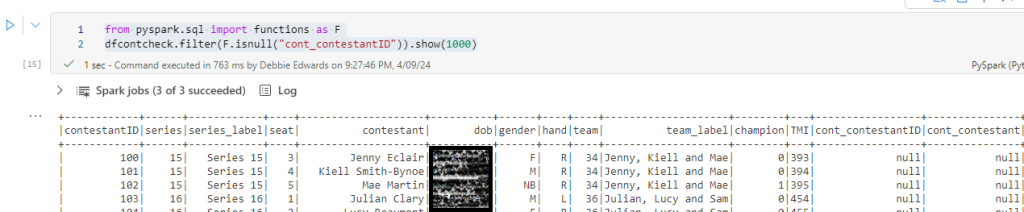
Filter for Null Values
from pyspark.sql import functions as F
dfcontcheck.filter(F.isnull("cont_contestantID")).show(1000)
72 records that don’t exist in dfattempt which is fine
from pyspark.sql import functions as F
dfcontcheck.filter(F.isnull("contestantID")).show(1000)
And none in attempts that are in people.
People is therefore our master data set and the PySpark code can be changed accordingly.
At the moment there is a lot of checks happening in the PySpark code. Once up and running and ready to be turned into a proper transformation notebook. All these checks could be removed if required to simplify.
Updating the Code with the new Logic
We are taking the code from Part 1 and completely updating based on the new findings
#Read the first file into a dataframe Teams
dfpeople = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/people.csv")
# dfattempts now is a Spark DataFrame containing CSV data from "Files/Data/Bronze/people.csv".
#And rename a couple of columns
dfpeopletransf = dfpeople.withColumnRenamed("id","contestantID").withColumnRenamed("name","contestant")
print(dfpeopletransf.count())
print(dfpeopletransf.distinct().count())
display(dfpeopletransf.distinct())
.withColumnRenamed brings back the dfpeople data set but renames the specified columns
Create dfCont to create our initial contestants DataFrame
Previously we had a lot of code blocks checking and creating Min IDs for a distinct contestant list. but now we have more of an understanding we can do this with less code.
#Lets immediately do the group by and min value now we know what we are doing to create a distinct list (Removing any IDs for a different series)
#import the function col to use.
from pyspark.sql.functions import col
#Creates the full distinct list.
dfcont = dfpeopletransf.groupBy('contestant', 'dob', 'gender','hand' )\
.agg(min('contestantID').alias('contestantID'),count('contestant').alias('TotalRecords'))
display(dfcont)
groupby. all the distinct values we want. Contestant, dob, gender and hand all are unique with the name. (Previously we just had contestant)
Next we agg (aggregate with min contestantID and cont the number of contestants as total records
If you are used to SQL you would see the following
SELECT MIN(contestantID) AS contestantID, contestant, dob, gender, hand, Count(*) AS TotalRecords
FROM dfpeopletransf
GROUP BY contestant, dob, gender, hand
Create a Current Age
# Create a Spark session
#spark = SparkSession.builder.appName("AgeCalculation").getOrCreate()
# Convert the date of birth column to a date type in dfCont
dfcont = dfcont.withColumn("dob", dfcont["dob"].cast("date"))
# add the current date and set up into a new dataframe
df = dfcont.withColumn("current_date", current_date())
#Calculate age using dob and current date
df = df.withColumn("age_decimal", datediff(df["current_date"], df["dob"]) / 365)
#Convert from decimal to int
df = df.withColumn("age", col("age_decimal").cast("int"))
#Convert Customer ID to int
df = df.withColumn("contestantID", col("contestantID").cast("int"))
#Update dfCont
dfcont = df.select("contestantID", "contestant", "dob","gender","hand", "age")
dfcont.show(1000)
It would be fun to filter by Age and Age Group. lets create the age first based on the current Date,
First of all we ensure date is a date .cast(“date”)
Then using .withColumn we add the current date to the data frame current_date()
Next. we use datediff to get the age from the date of birth and the current date
Set age to int and customerID to int
Next update dfCont with the full list of columns (Excluding current_date because that was only needed to create the age.
Create Age group
from pyspark.sql import SparkSession
from pyspark.sql.functions import when, col
# Create a Spark session
#spark = SparkSession.builder.appName("ConditionalLogic").getOrCreate()
# Apply conditional logic
dfcont = dfcont.withColumn("ageRange", when(col("age") < 20, "0 to 20")
.when((col("age") >= 20) & (col("age") <= 30), "20 to 30")
.when((col("age") >= 30) & (col("age") <= 40), "30 to 40")
.when((col("age") >= 40) & (col("age") <= 50), "40 to 50")
.when((col("age") >= 50) & (col("age") <= 60), "50 to 60")
.otherwise("Over 60"))
# Show the result
dfcont.show()
We have created what would be a CASE in SQL
using .WithColumn to create a new column. .when.otherwise are used to create this new data item
Create New Row for -1 NA Default Row
We are back to almost the original code. Creating our Default row but this time with more columns
from pyspark.sql import SparkSession
from pyspark.sql import Row
# Create a sample DataFrame
data = [(-1, "Not Known","1900-01-01","NA","NA","0","NA")]
columns = ["contestantID", "contestant", "dob", "gender", "hand", "age", "ageRange"]
new_row = spark.createDataFrame(data, columns)
# Union the new row with the existing DataFrame
dfcont = dfcont.union(new_row)
# Show the updated DataFrame
#dfcont.show(1000)
dfcont.show(1000)
We can now see Not known in the list
Running a DISTINCT just in case we applied the above more than once.
#Just in case. We distinct again to remove any extra NA Rows
dfcont = dfcont.distinct()
dfcont.show(1000)
Checking we have unique Contestants GROUPBY
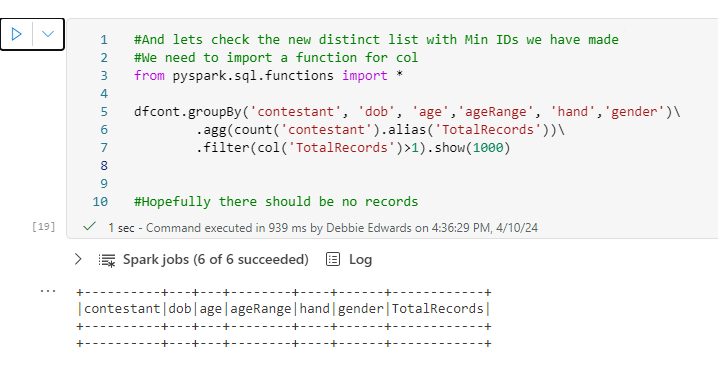
#And lets check the new distinct list with Min IDs we have made
#We need to import a function for col
from pyspark.sql.functions import *
dfcont.groupBy('contestant', 'dob', 'age','ageRange', 'hand','gender')\
.agg(count('contestant').alias('TotalRecords'))\
.filter(col('TotalRecords')>1).show(1000)
#Hopefully there should be no records
We have all unique contestants, including the extra information we have added to the dimension.
Creating the Contestant Key
We can now create slightly better code than Part 1 using less code blocks
#Now finally for this we need a Key a new column
# Imports Window and row_number
from pyspark.sql import Window
from pyspark.sql.functions import row_number
# Applying partitionBy() and orderBy()
window_spec = Window.partitionBy().orderBy("ContestantID")
# Add a new column "row_number" using row_number() over the specified window
dfcont = dfcont.withColumn("ContestantKey", row_number().over(window_spec)- 2)
# Show the result
dfcont.show(1000)
Previously a partition column with the value 1 was added so we could do the following: .partitionBy(“partition”)
But simply using partitionBy() and not including a column removes the need for the extra code and column and does the same thing.
Adding the Team
Previously the Team was added from attempts.csv but we know that we can change this to people now and have better team information.
#Creates the full distinct list.
dfContTeam = dfpeopletransf.select(col("contestantID").alias("teamcontestantID"), col("contestant").alias("teamContestant"),
col("team").alias("teamID"),col("team_label").alias("TeamName")).distinct()
display(dfContTeam)
Remove Rows with Empty team information
#Now remove the rows with null teamids
# Import necessary libraries and create a Spark session
#from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[1]").appName("SparkByExamples.com").getOrCreate()
# Drop rows with NULL values in the "id" column
dfContTeam = dfContTeam.na.drop(subset=["teamId"])
# Show the filtered DataFrame
dfContTeam.show(truncate=False)
Join team to Contestant
#Now what we want to do is add TeamName into dfcont
dfcont = dfcont.join(dfContTeam, dfcont["contestant"] == dfContTeam["teamContestant"], how="left").drop(dfContTeam.teamContestant).drop(dfContTeam.teamcontestantID)
display(dfcont)
This time we cleaned up the code by adding the two columns to drop in the above statement so we don’t have two names and IDs from both data sets.
Create DELTA PARQUET TABLE
from delta.tables import DeltaTable
dfcont.write.mode("overwrite").format("delta").saveAsTable("dimContestant")
Because we are overwriting our new data set should overwrite our old Dimension. However, there will be conflict issues because the schema is so different so for this exercise, The files will be removed before being re-added.
We now have options of using the Delta PARQUET, or just the PARQUET File.
Conclusion
In Part 1 we used attempts csv for contestants. For Part 2 we did lots of analysis and checked that actually, people was a better data source for contestants. So we changed the input for the initial DataFrame to people.csv
We also used the opportunity to tidy up the code, now we are getting to grips with Pyspark as an alternative to SQL.
Next on the list is to create more dimensions.
Dim Task
Dim Episode
Dim Date
And the Taskmaster Stats Fact Table
Then to do some analysis, using the inbuilt visuals in a Notebook, and Power BI.
Its so exciting at the moment with all the changes going on in the world of Microsoft and I wanted to use the trial version of Fabric to see if I could move my ‘standard’ working practices over into Fabric.
The first thing was to find a practice dataset for this exercise so of course I went for my favorite stats based show. UK Taskmaster.
Kaggle
Kaggle delivered the goods with csv files of taskmaster information
The challenge is to deliver a star schema from this data. Transforming it and creating Dims and Facts for the ultimate goal of a star schema.
CSV – SQL DB – Power BI
Usually I use Data factory to pull the data into a SQL database. In here I create Stored procedures to transform the data. These stored procedures are then added into the pipeline so we can rerun when needed.
Finally, the dimensions and facts are imported into Power BI from the Dims and Facts in the SQL Database.
So the question is. can I transform my files using Pyspark within a Notebook, and then create the Dim and Fact tables in DELTA PARQUET
I have used SQL for over 20 years and its my weapon of choice so this is going to be a real puzzler of a task.
Getting Started – Create the Fabric Workspace
I have my Fabric Trial and a Workspace added to the Fabric Trial.
Here I have just Added a new Project. to Devlops Debbies Training
Visual Studio
I am going to use Visual Studio for the next task, but there are lots of other ways you can do this next step
And connect to the repository that has been created (You need to log in to see your repos)
Click clone and you will then have a local copy of the code base. it doesn’t support everything at the moment but it does support Notebooks, which is what will be used for this exercise.
We will go back to the repos Soon to start using it.
Create a Delta lake in your Fabric Workspace in Data Engineering Fabric Experience
Clicking on data Engineering takes you to the Data engineering area of fabric where you can set up a Lakehouse.
I have simply called the Lakehouse DebbiesFabricLakehouse
When the Data Lakehouse is completed you get the following
And for the time being, Lets just use Lakehouse.
Add CSV Files into the Lakehouse
Notice that we have the following folders in the Lakehouse
For this project, the medallion architecture is being used.
Bronze is where the csv files are stored in the lakehouse. the raw data zone
Silver is the transformed PARQUET data will go (Which we will look at later)
Gold is the final transformed STAR SCHEMA layer. The curated zone.
I have all the taskmaster csv files and I am going to simply upload them to the Lakehouse Files / Data / Bronze folder
Refresh the folder and you should see your files in the pane.
Create the Notebook
Now we can start to work with the files and here is where the fun starts. Instead of a pipeline that pulls data into SQL before the transformations, Lets create a Notebook
We are ready to go. this is what I can see to the right of the code pane.
And Pyspark will be the Spark language of choice. I wont use any SQL just to see how it goes, away from my beloved SQL.
I am doing very simple code at the moment and hope make it better and better the further I get so lets just start adding Pyspark and markdown (Descriptions)
#Read the first file into a DataFrame
dfattempts = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/attempts.csv")
# dfattempts now is a Spark DataFrame containing CSV data from "Files/Data/Bronze/attempts.csv".
display(dfattempts)
Now we read our first csv into a data frame. A DataFrame is basically a table of data.
We can click on the play icon to run this part of the code. We can now start transforming.
Contestant transformation
The first thing I want to do it get out contestants. Create a unique key and add the key to the Dim table and the transformation table which still contains all the facts.
(I have gone back and forth in the code as I have worked on it so some code has been amended when certain issues have come to light)
#We will use this later in the process. the Following code renames the columns from the original data frame but brings back the entire dataframe again
#We actually only need the contestant part
dfattempttrns = dfattempts.withColumnRenamed("contestant","contestantIDToRemove").withColumnRenamed("contestant_label","contestantToRemove")
dfattempttrns.printSchema()
print(dfattempttrns.count())
print(dfattempttrns.distinct().count())
display(dfattempttrns.distinct())
A Transformed DataFrame is created from the main DataFrame and initially, two items have been renamed. contestant to contestantIDToRemove and contestant_label to contestantToremove. We will see why later.
We also print the count of contestants and we display the transformed data frame.
Create Contestants Dim
The line from pyspark.sql.functions import col imports the col function from the pyspark.sql.functions module
Here is an explanation of what it does.
Pyspark is a Python library used for working with big data and performing distributed data processing using Apache Spark.
The pyspark.sql.functions module provides a set of built in functions that can be used for data manipulation and transformation in Spark DataFrames.
The col function is one of these built in functions. It is used to:
Reference a column in a DataFrame.
You can use it to: Select a specific column.
Apply mathematical operations to a specific column. Create new columns based on existing ones
#import the function col to use.
from pyspark.sql.functions import col
#Creates the full distinct list.
dfcont = dfattempts.select(col("contestant").alias("contestantID"), col("contestant_label").alias("contestant")).distinct()
display(dfcont)
This code gives us a distinct list of Contestant IDs and Names and we have aliased the new names in this DataFrame. this uses our original first DataFrame, not the transformed one.
This code block just orders the data. The interesting part of the code here is that instead of display we use show to print out the DataFrame. If you leave it as show() only 20 rows are printed.
If you leave the code at show() only 20 rows are returned
Create a DataFrame of values
This is for information only. I wanted to see how a DataFrame is created of information specified in the code block.
from pyspark.sql import SparkSession
In PySpark, the SparkSession class serves as the entry point for programming with the Dataset and DataFrame API. It allows you to create DataFrames, register them as tables, execute SQL queries, cache tables, and read Parquet files.
From pyspark.sql import Row
In PySpark, the Row class is used to represent a row of data in a DataFrame. Each field in a Row object can be accessed by its name or index.
#https://saturncloud.io/blog/adding-new-rows-to-pyspark-dataframe-a-comprehensive-guide/
#Just for information. Not being used but here is how you write your own dataframe
from pyspark.sql import SparkSession
from pyspark.sql import Row
#I dont think I need this because I already have a spark session?
#spark = SparkSession.builder.appName('AddRows').getOrCreate()
data = [(70, 'Sam Campbell'),
(71,'Julian Clary'),
(72,'Lucy Beaumont'),
(73,'Sue Perkins'),
(73,'Susan Wokoma')]
columns = ["contestantID", "contestant"]
dfnarowCont = spark.createDataFrame(data, columns)
dfnarowCont.show()
Create a New Row for the default NC Row
for a dimension we always have a default row of Not Known and a key of -1. For example if we are looking at Customer orders and a customer hasn’t bought anything this month
DateKey
Customer Key
Quantity
01012022
56
244
01012022
-1
0
Here we have -1 in the fact dimension so we can then bring through all the default Not known descriptors from the customer table if we need to, when analysing in Power BI.
from pyspark.sql import SparkSession
from pyspark.sql import Row
# Create a sample DataFrame
data = [(-1, "Not Known")]
columns = ["contestantID", "contestant"]
new_row = spark.createDataFrame(data, columns)
# Union the new row with the existing DataFrame
dfcont = dfcont.union(new_row)
# Show the updated DataFrame
#dfcont.show(1000)
dfcont.show(1000)
Now, lets run a distinct, in case we have run the above code numerous times and we have multiple default rows.
#Just in case. We distinct again to remove any extra NA Rows
dfcont = dfcont.distinct()
dfcont.show(1000)
Our Dimension should consist of unique values. So we need to test our new dataset
from pyspark.sql.functions import *
dfcont.groupBy('contestant')\
.agg(min('ContestantID').alias('MinContestantID'),count('contestant').alias('TotalRecords'))\
.filter(col('TotalRecords')>1).show(1000)
Notice we don’t have dfcont = Because this loads the results into a data frame. here we are just looking at the data frame. It is basically just a SELECT statement
agg is used to calculate more than one aggregate (multiple aggregates) at a time on grouped DataFrame.
So to perform the agg, first, you need to perform the groupBy() on DataFrame which groups the records based on single or multiple column values, and then do the agg() to get the aggregate for each group.
The only thing that makes these values none distinct is that they will have different ContestantIDs. So this query is bringing back the min(ContestantID)
Here we can see that we do have some bad data that we can transform and correct so everything in both the dim and the transformation tables holds the min ID
Create a DataFrame of all contestants with Min Contestant ID
Lets set a DataFrame and use it to update. We bring back the entire contestant list with the min IDs only. Creating a distinct list
#We need to import a function for col
from pyspark.sql.functions import *
dfminContID = dfcont.groupBy('contestant')\
.agg(min('ContestantID').alias('MinContestantID'),count('contestant').alias('TotalRecords'))
dfminContID.show(1000)
GROUPBY and AGG and FILTER
Group on Contestants
Aggregate gives us a count of contestants called TotalRecords
Then we filter to only find records where TotalRecords is greater than 1
Lets check the new distinct list with Min IDs we have made
#We need to import a function for col
from pyspark.sql.functions import *
dfminContID.groupBy('contestant')\
.agg(count('contestant').alias('TotalRecords'))\
.filter(col('TotalRecords')>1).show(1000)
JOIN two DataFrames Where JOIN Columns are the same
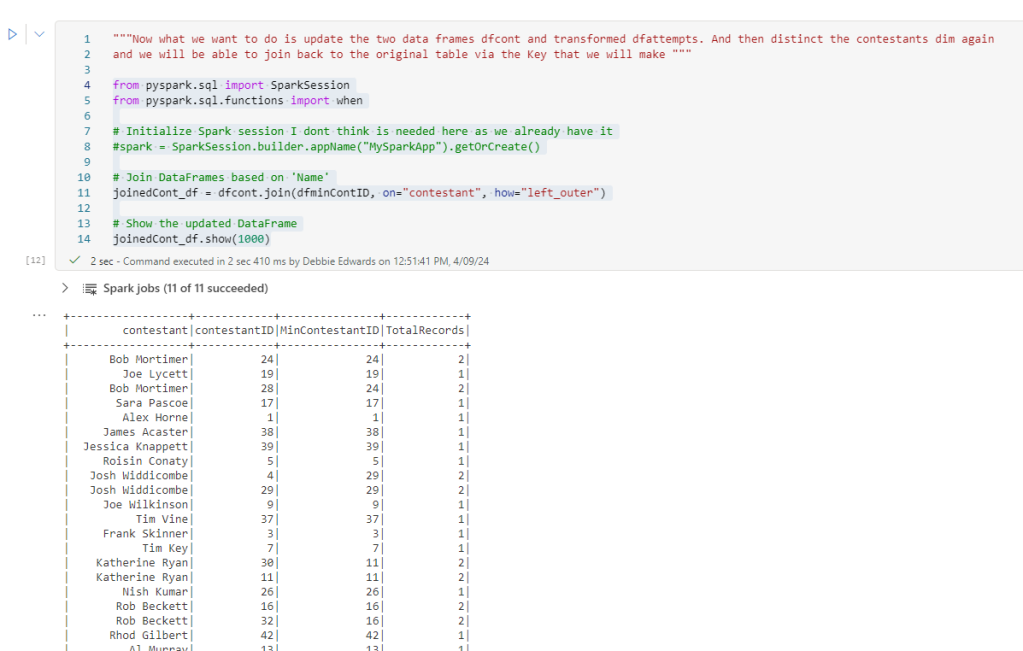
Now what we want to do is update the two DataFrames dfcont with Min ID’s.
from pyspark.sql import SparkSession
from pyspark.sql.functions import when
# Initialize Spark session I dont think is needed here as we already have it
for the next step lts reupdate dfCont with our updated min value
#We want to reset back to ContestantID and Contestant, this is a distinct List
dfcont = joinedCont_df.select(col("minContestantID").alias("contestantID"), col("contestant")).distinct()
dfcont.show(1000)
We updated ContestantID with MinContestantID
So, we have reset the ContestantID with the correct min ID
You can’t modify the existing dataframe as it is immutable, but you can return a new dataframe with the desired modifications.
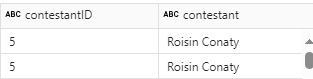
Recheck a specific contestants data – Filter
Lets do a filter on a contestant we know had a duplicate ID
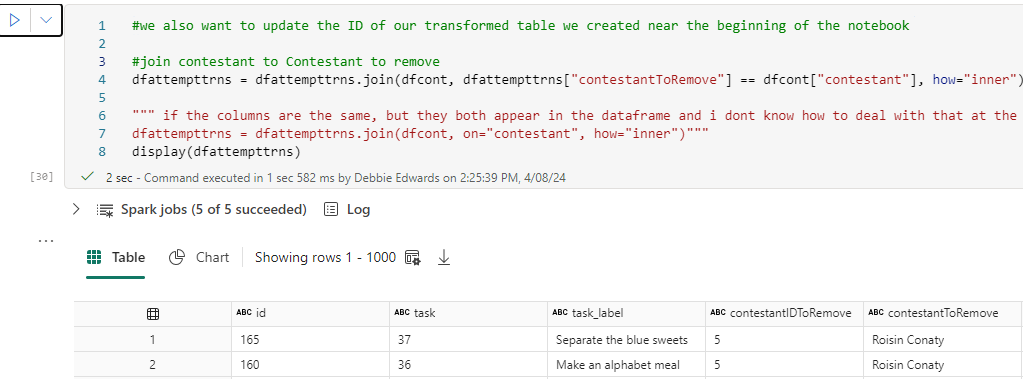
We also want to update the Contestant ID of our transformed table (dfattempttrns) we created near the beginning of the notebook. Eventually we can create a fact table from dfattempttrns with Contestant Keys, so we want to join them via the ContestantID.
this is where the data items contestantIDTORemove and contestantToremove comes in handy
#we also want to update the ID of our transformed table we created near the beginning of the notebook
dfattempttrns = dfattempttrns.join(dfcont, dfattempttrns["contestantToRemove"] == dfcont["contestant"], how="inner")
dfattempttrns = dfattempttrns.join(dfcont, on="contestant", how="inner")"""
display(dfattempttrns)
There are two extra columns at the end from our corrected dfcont DataFrame.
the join was on the contestantname
#Lets have a look at the schema
dfattempttrns.printSchema()
Here we have a little code to display the Schema of the updated dfattemptstrans DataFrame
And just to be sure we can now check for our Contestant again
#Lets do a filter on a contestent we know had a duplicate ID
#dfattempttrns.filter(dfattempttrns.contestant == "Noel Fielding").show(1000)
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
dfattempttrns.select(col("contestantID"), col("contestant")).filter(dfattempttrns.contestant == "Noel Fielding").distinct().show(1000)
Its now working. there is only one record in both the transformation table and the dimension table so the join on ID’s will work.
Creating the Dim Key – Adding a column .WithColumn
For contestants Dim we need a Key. So we need a new column. Lets add a new column to create the partition on. I’m sure there are lots of ways to do this and later in the process I will be able to really hone the code down with more Pyspark knowledge.
from pyspark.sql.functions import lit
# add column for discount
dfcont = dfcont.withColumn("Partition", lit(1))
# display the dataframe
dfcont.show(1000)
Create the Contestant Key using Partition by
#Now finally for this we need a Key a new column
# Imports Window and row_number
from pyspark.sql import Window
from pyspark.sql.functions import row_number
# Applying partitionBy() and orderBy()
window_spec = Window.partitionBy("Partition").orderBy("ContestantID")
# Add a new column "row_number" using row_number() over the specified window
dfcont = dfcont.withColumn("ContestantKey", row_number().over(window_spec)- 2)
# Show the result
dfcont.show(1000)
Use – 2 which starts the ID no at -1 (-1,0) so the default can have the -1 key as standard
from pyspark.sql import Window
Imports the Window class from the pyspark.sql module123.
The Window class is used to define a window specification in the DataFrame API2. A window specification is defined by specifying partitioning expressions and ordering expressions2.
The partitioning expressions are used to partition the data into groups, and the ordering expressions are used to order the data within each group2.
from pyspark.sql.functions import row_number
The row_number function from the pyspark.sql.functions module is used to assign a unique row number to each row in a DataFrame.
It is commonly used in Spark SQL to create a sequential identifier for rows based on a specified order.
because the NA ID is -1 for the default row it immediately gets the Key of -1 because of the order which is just what we wanted.
#We want to remove the partition key from the dim
dfcont = dfcont.select(col("contestantKey"), col("contestantID"), col("contestant")).distinct()
dfcont.show(1000)
Adding Team to Dim Contestant
there is another item we want to add into the contestant dim. The Team.
First of all, lets get a distinct list of everything we need from dfattempttrns. Namely. the contestantID and Contestant, TeamID and TeamName (These two are new, we haven’t worked with them so far)
#import the function col to use. But shouldnt it already be available?
#from pyspark.sql.functions import col
#Creates the full distinct list.
dfContTeam = dfattempttrns.select(col("contestantID").alias("teamcontestantID"), col("contestant").alias("teamContestant"),
col("team").alias("teamID"),col("team_label").alias("TeamName")).distinct()
display(dfContTeam)
The original DataFrame includes the tasks and team is only set on a team task. In Contestants we simply want to know which team the contestant is in.
we have created a new DataFrame called dfContteam
Remove rows with NULL team IDs
# Import necessary libraries and create a Spark session
##from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[1]").appName("SparkByExamples.com").getOrCreate()
# Drop rows with NULL values in the "id" column
dfContTeam = dfContTeam.na.drop(subset=["teamId"])
# Show the filtered DataFrame
dfContTeam.show(truncate=False)
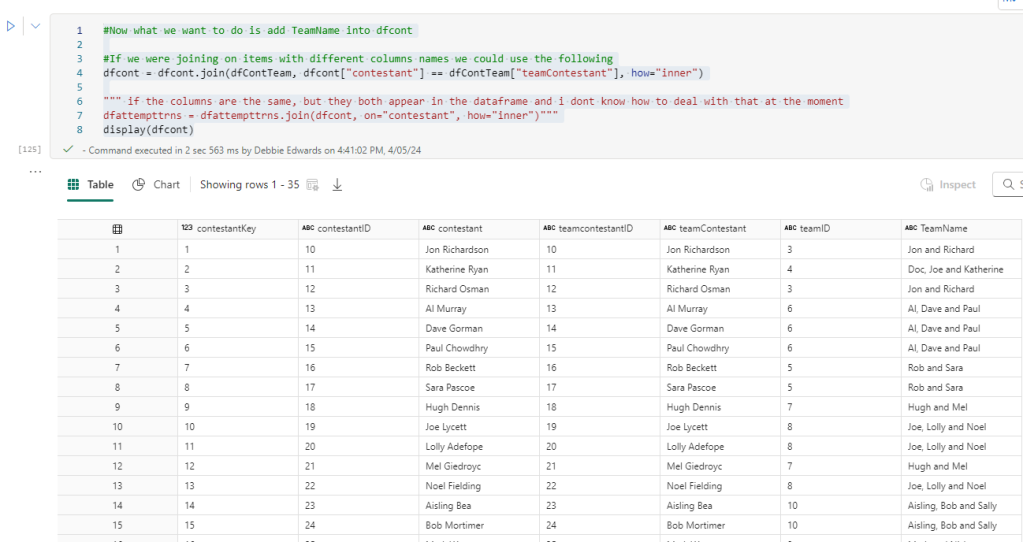
Join tables to add team to contestants Dim using the contestant Name
#Now what we want to do is add TeamName into dfcont
#If we were joining on items with different columns names we could use the following
dfcont = dfcont.join(dfContTeam, dfcont["contestant"] == dfContTeam["teamContestant"], how="inner")
dfattempttrns = dfattempttrns.join(dfcont, on="contestant", how="inner")"""
display(dfcont)
When the dfContTeam was created. Contestants was called teamContestant and this is the join you see in the code.
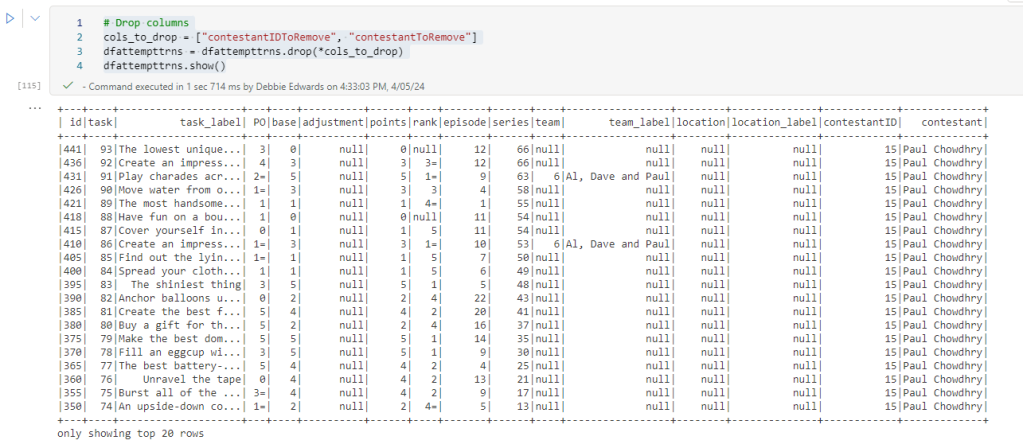
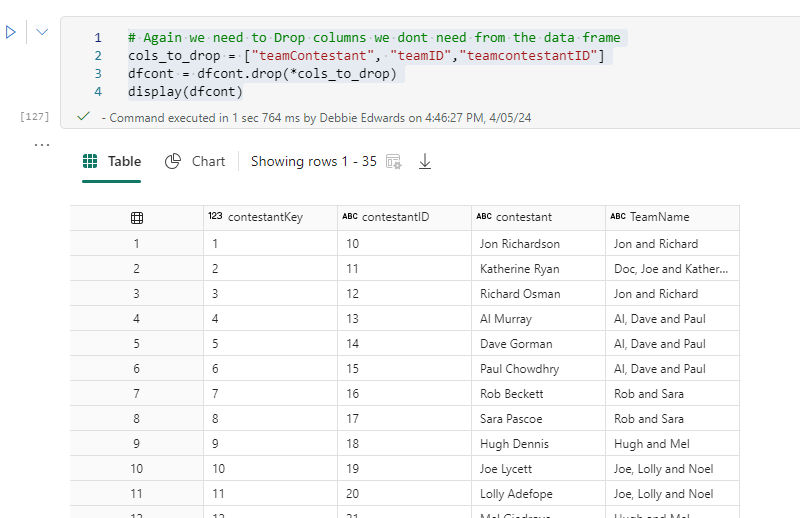
Drop Columns
# Again we need to Drop columns we don't need from the data frame
cols_to_drop = ["teamContestant", "teamID","teamcontestantID"]
dfcont = dfcont.drop(*cols_to_drop)
display(dfcont)
Finally. A Dim Contestant DataFrame with everything we need.
Adding ContestantID into the transformed DataFrame
Before creating a PARQUET File it would be good to get the Contestant Key into the transformed table by joining the tables again on contestantID
#join contestant to Contestant to remove
dfattempttrns = dfattempttrns.join(dfcont,
dfattempttrns["contestantID"] == dfcont["contestantID"],
how="inner").drop(dfcont.contestantID).drop(dfcont.contestant)
display(dfattempttrns)
We now have .drop(dfcont.contestantID).drop(dfcont.contestant) in the code which removes our duplicate columns before they are added into the transformation table
UPDATE – We have learned how to update using different column names AND Update using the same column name, whilst removing any columns from table B that are identical to table A
Creating the DELTA PARQUET FILE
Finally we can add Dim Contestants to a PARQUET file. We don’t need any partitions because its just a small dim table.
from delta.tables import DeltaTable
dfcont.write.mode("overwrite").format("delta").saveAsTable("dimContestant")
After a refresh on tables
this creates a Delta Lake table called DimContestant which is stored in Delta Format and provides ACID Transactions. for example, Time travel and versioned data.
The Black triangle icon means that it is a DELTA PARQUET file.
This saves the DataFrame as a Parquet file into a specific folder in Files.
Its columnar storage that works really well for analytics workloads but doesn’t support ACID DeltaLake transactional support live time travel mentioned above.
Lets have a look at what we have created (the data is none partitioned)
A PARQUET File is a columnar storage file. In the same way as Power BI has a columnar data store when you import the data.
Our data is in the snappy.parquet file.
The Success File is not a specific file format. Its the concept related to the execution so here we can see that the creation of the file was a success.
So:
Delta Lake PARQUET with advanced features and transactional capabilities. Tables have to be in Tables folder in order to be recognized by other engines like SQL endpoint and semantic model.
PARQUET for storage and simplicity. But are only visible for Spark?
We will look at these both in more detail in a later exercise.
Stopping the Spark Job
Its always worth stopping the Spark job at the end of processing
spark.stop()
It will stop automatically after a time but this ensures that the process is stopped immediately upon the end of the transformation process
Using Source Control
Clicking back on the workspace. We added our workspace to Devops. So now we can see that there has been a change.
when working with other people there will be feature branches to connect to rather than main but because this is just a one person exercise. Committing to main is fine for the time being.
And in Devops we can see that the code has been committed.
Conclusion
We have taken an example group of csv files and transformed them so far to create one dimension for a star schema.
This dimension data will be added into a star schema via the contestant key.
We have also set up Devops to commit the notebook code into the GIT repository.
In later posts we will move on to other dimensions. Create the fact tables and see what we can do with both the DELTA PARQUET and PARQET Files.