
Parts 1 2 3 and 4 were attempting to transform data into a star schema for power BI using notebooks in fabric.
However there was missing data which meant we couldn’t go to the level of detail we wanted for the star (Episode level)
Now we have a new data set and the csv files have been transferred into a data lake manually.
We can attempt to set up a pipeline to import the data in another blog.
in Microsoft Fabric we go to data Engineering

And open up the Fabric Workspace.
We already have a Lakehouse and notebooks containing the work from the last few blog posts
Lets open the Lakehouse

Although we are using the medallion architecture, you may still wish to call your folders, for example raw and staging .



Create a Shortcut
For this exercise we are going to do something different and have the raw data in a datalake in Azure that we add a shortcut to.
the Files have been placed in a datalake and we want to shortcut to these files. Imagine that the process is already in place pre Fabric and we have decided to stick with this process.

This will be added to every time a series finishes.
We also have a Lookup contestants file in this folder that will be updated by having data appended to it

This new exercise will work with partitioning by series for the fact table. Back in Fabric.

Lets add a Shortcut to our new Taskmaster folder in the Bronze raw data area.
https://learn.microsoft.com/en-us/fabric/onelake/onelake-shortcuts

We need the connection settings. get this from the Data Lake. Endpoints Data lake Storage, Primary endpoint data lake storage and sign in.

Tip Make sure you have Storage Blog Data Contributor Role
You want the URL with dfs (Distributed File System), not blob.
However, note that the Data Lake is in North Europe.
Creating a shortcut to a data lake in a different geographical area can result in Egress charges
So we need to check that our Data Lake and Lakehouse are in the same area.
Go back to the Workspace and Workspace Settings

Thankfully both are in North Europe so this should be fine.
Note. To keep down Egress charges you can set up caching which keeps the files for 24 hours without needing to access the data in the shortcut. but this is only available for
- GCS (Google Cloud Storage)
- S3 (Amazon S3 Simple Storage Service)
- S3 compatible shortcuts (Any Services using Amazon Simple Storage Service)
Back to our Shortcut. Click Next.
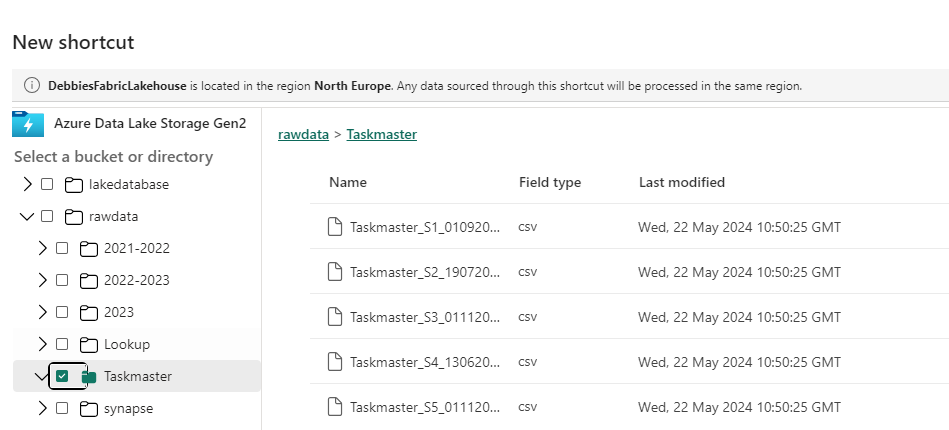
We want to create a Shortcut to the Taskmaster Folder in the raw Folder. Click Next

Click Create

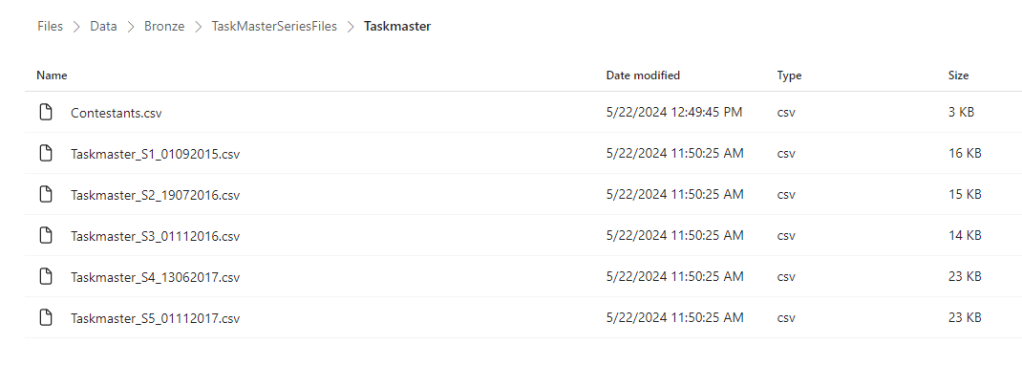
We now have a shortcut set up to the Azure Data Lake. Later on we can add another file and see what happens.
Create a Notebook

Lets Create a New Notebook
%%configure
{
"defaultLakehouse": {
"name": "DebbiesFabricLakehouse"
}
}First of all I’m going to configure to the current Lakehouse
Load in all the files in the Shortcut Folder
from pyspark.sql.functions import input_file_name, regexp_extract
dftm = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/TaskMasterSeriesFiles/Taskmaster/Taskmaster_*.csv")
dftm = dftm.withColumn("filename", regexp_extract(input_file_name(), r"([^/]+)$", 1))
display(dftm)- * alias has been used to get all series files and Series End Dates, and Only csv files.
- input_file_name() brings us back the file name
- regexp_extract(, r”([^/]+)$”, 1)) allows us to remove the URL and just keep the filename.
The File name may be important later.

Remove empty records
We have some null rows come through that we want to remove from the data set

how=’all’
This parameter is used with dropna() to drop rows where ALL values are NULL
Removing Special characters
There are issues. We have some strange characters coming through in the data set.
We can use a filter function on the col Column episode name LIKE and bring through a distinct list.
from pyspark.sql.functions import regexp_replace
# Replace '�' with 'eclair' in the 'text' column
dftm_cleaned = dftm.withColumn("Episode Name", regexp_replace("Episode Name", "A pistachio �clair", "A pistachio eclair"))
# Replace any remaining '�' with an empty string
dftm_cleaned = dftm_cleaned.withColumn("Episode Name", regexp_replace("Episode Name", "�", "'"))
# Show the resulting DataFrame
display(dftm_cleaned)We have two.
é in eclair and any item with ‘
So we actually need to update based on Logic:
from pyspark.sql.functions import regexp_replace
# Replace '�' with 'eclair' in the 'text' column
dftm_cleaned = dftm.withColumn("Episode Name", regexp_replace("Episode Name", "�", "eclair"))
# Replace any remaining '�' with an empty string
dftm_cleaned = dftm_cleaned.withColumn("Episode Name", regexp_replace("Episode Name", "�", ""))
# Show the resulting DataFrame
dftm_cleaned.show(1000)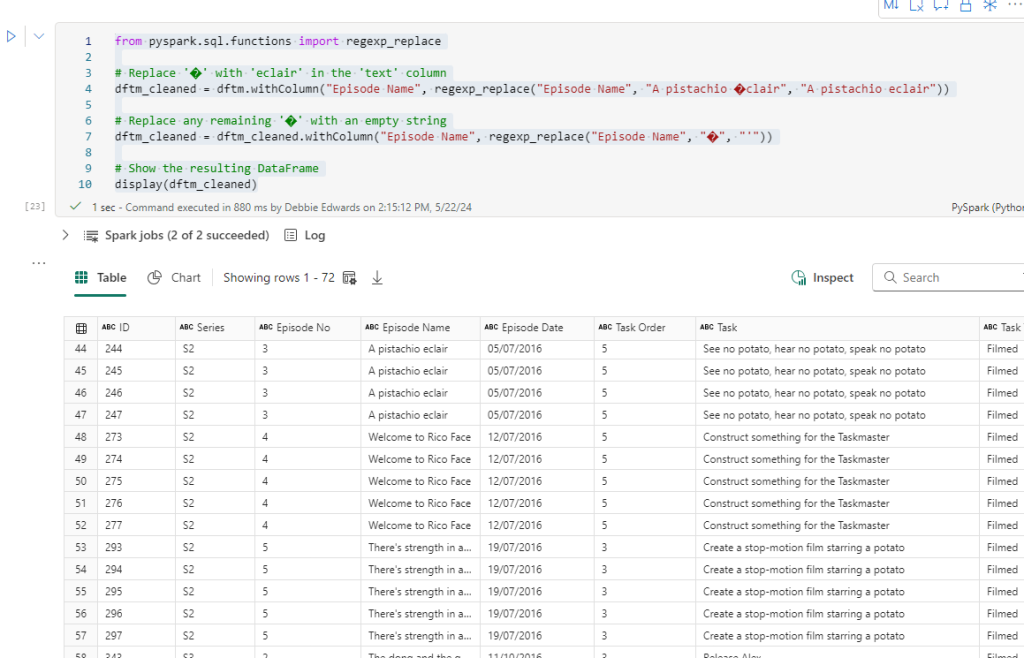
regexp_replace
This function replaces all substrings of a string that matches a specified pattern with a replacement string. Good for cleaning and transformation.
it might be best to check task name too by repeating the above filter and changing Episode name to Task.

we have Greg says…
and the rest are ‘
We can also deal with this
from pyspark.sql.functions import regexp_replace
# Replace '�' with 'eclair' in the 'text' column
dftm_cleaned = dftm_cleaned.withColumn("Task", regexp_replace("Task", "Greg says�", "Greg says..."))
# Replace any remaining '�' with an empty string
dftm_cleaned = dftm_cleaned.withColumn("Task", regexp_replace("Task", "�", "'"))
# Show the resulting DataFrame
display(dftm_cleaned)Create Dim episode Dimension
Lets have a look at just S1. Does it have all the Episodes?

Yes it looks good. So the episode Dimension consists of Series and Episode.
from pyspark.sql.functions import to_date
dftmEp = dftm_cleaned.select("Series","Episode No" ,"Episode Name").distinct()
dftmEpOrdered = dftmEp.orderBy(col("Series"),col("Episode No"))
display(dftmEpOrdered)This is a Distinct List

And we have created an OrderBy Data Frame to display.
There is an empty row we need to remove
##drop all rows with null values
dftmEp = dftmEp.na.drop(how='all')
display(dftmEp)
We have used this code block before to remove the fully null rows.
Add A Default Row
from pyspark.sql import SparkSession
from pyspark.sql import Row
# Create a sample DataFrame
data = [(-1, -1,"Not Known")]
columns = ["series", "episode No", "Episode Name"]
new_row = spark.createDataFrame(data, columns)
# Union the new row with the existing DataFrame
dftmEp = dftmEp.union(new_row)
# Show the updated DataFrame
dftmEp.show(1000)

Now we have the recommended Default row. It’s time to add a key
from pyspark.sql.functions import col
# Create a window specification partitioned by "Series" and ordered by "Episode No"
window_spec = Window.orderBy(col("Series"), col("Episode No"))
# Add a new column "EpisodeKey" using row_number() over the specified window
dftmEpKey = dftmEp.withColumn("EpisodeKey", row_number().over(window_spec) - 2)
# Show the result
dftmEpKey.show(1000)Window.OrderBy
This function is used to define the ordering within a window specification. It allows you to specify the order in which rows are processed within a partition
row_number().over
The ROW_NUMBER() function, when used with the OVER() clause, assigns a sequential integer number to each row in the result set of an SQL query.

Create Delta PARQUET File
We have our first dimension. Lets add it to Silver folder in files as unmanaged and Tables as a managed Delta PARQUET table. that way we can see what we can do with both
We don’t want to partition the dimension. The Fact table will be partitioned
from delta.tables import DeltaTable
dftmEpKey.write.mode("overwrite").option("overwriteSchema", "true").format("delta").saveAsTable("dimEpisode")However, There is an error coming up
AnalysisException: Found invalid character(s) among ‘ ,;{}()\n\t=’ in the column names of your schema. Please upgrade your Delta table to reader version 2 and writer version 5 and change the column mapping mode to ‘name’ mapping. You can use the following command:
Instead of upgrading. We want to remove the special characters. The columns are
|Series|Episode No| Episode Name|EpisodeKey|
Cleaning up Columns in a dataframe
import re
# Select columns with modified names (without special characters)
dftmEpKey_cleaned = dftmEpKey.select(*[col(c).alias(re.sub('[^0-9a-zA-Z]', '', c)) for c in dftmEpKey.columns])
# Show the result
dftmEpKey_cleaned.show(1000)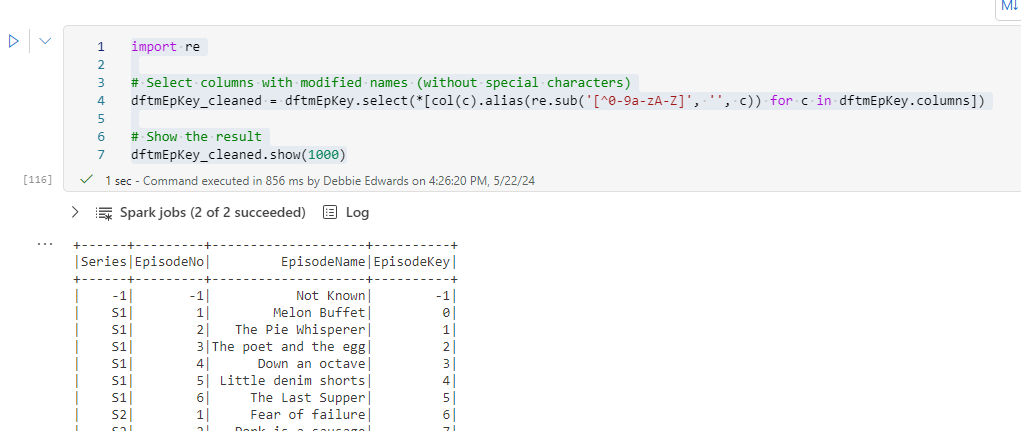
It seems it may have been the spaces.
re.sub
In PySpark, the re.sub() function is used to replace substrings that match a specified regular expression pattern with a string of your choice.:
re.sub('[^0-9a-zA-Z]', '', c) removes any characters that are not alphanumeric (letters or digits) from the column name.
The expression [col(c).alias(re.sub('[^0-9a-zA-Z]', '', c)) for c in dftmEpKey.columns] is a list comprehension that performs the following steps for each column name (c):
col(c).alias(...)creates a new column with the modified name (without special characters) using thealias()method.
from delta.tables import DeltaTable
dftmEpKey_cleaned.write.mode("overwrite").option("overwriteSchema", "true").format("delta").saveAsTable("dimEpisode")And we can save to delta PARQUET
from delta.tables import DeltaTable
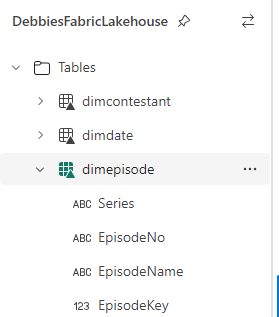

So, we now have an episode dimension. lets save the Notebook as Dim Taskmaster Episode V2 (We already have the original one saved)
Remember to commit in Source Control.
We want to create Task and Contestant dimensions. We already have a date dimension to work with.
In the next post, these extra dimensions and fact table will be created. and then we can see how they can be used
