In part 4. A new Data source was used at task level and the first dimension was added. Lets quickly create the rest of the dims.
Then we are ready to move on to the next steps in Fabric.
Creating a Silver transformed layer
There are a few changes that would be good to make to the notebooks. The base data needs a level of transforming before we kick off with Dims and Facts.
It would be good to save the transformed data once in the Silver layer and then use this PARQUET file to work from. This means we never have to repeat any code for dims and facts.
We want
- Silver Transformed data as PARQUET unmanaged files
- Gold Dims and facts in Delta PARQUET Managed tables
Taskmaster Transformed Data
Create a new Notebook
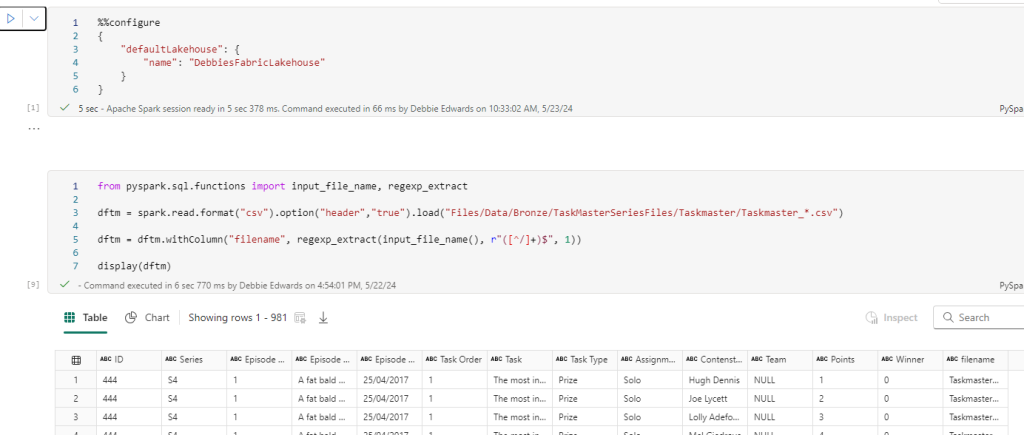
##drop all rows with null values just in case
dftm = dftm.na.drop(how='all')
display(dftm)Just in case. Get rid of Empty Rows
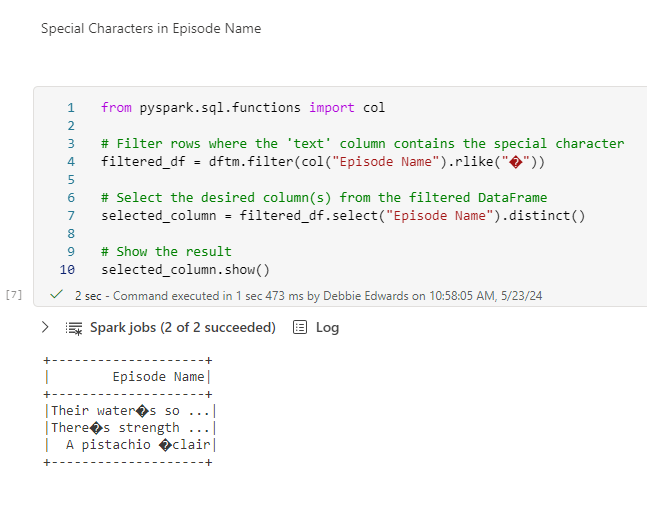
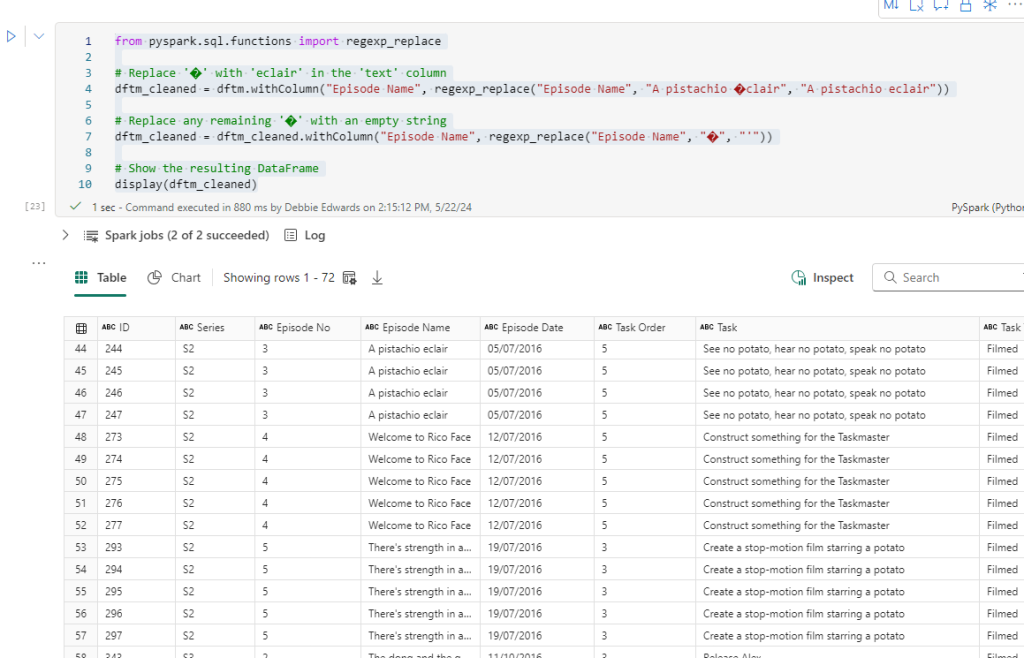
Clean Special Characters
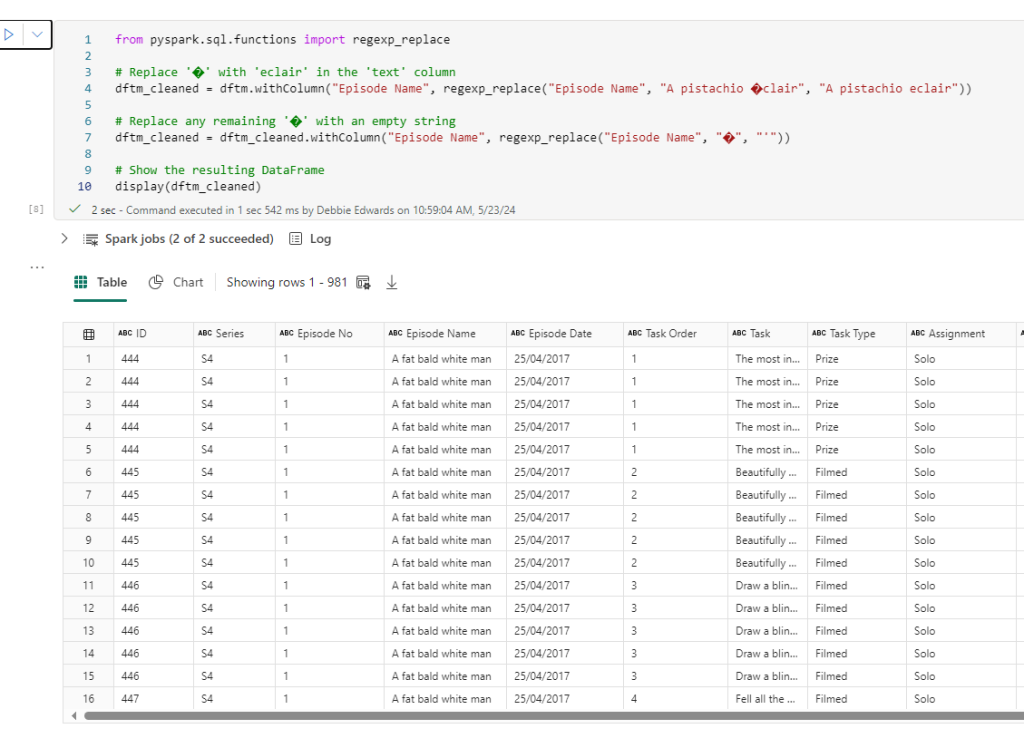
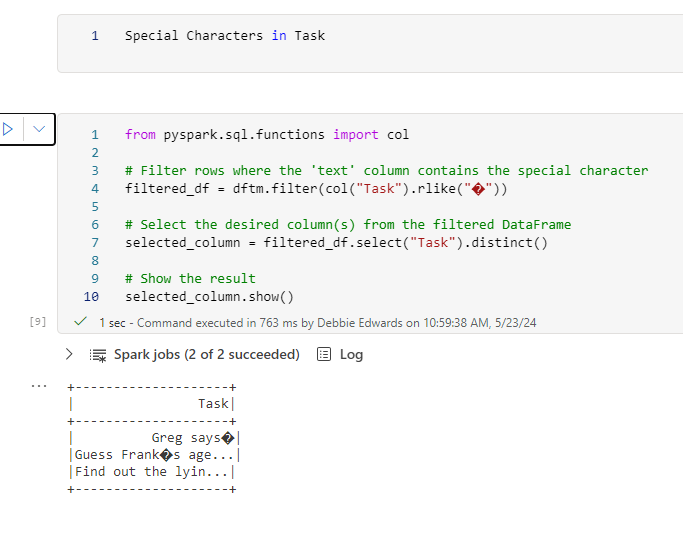
Clean Special Characters in Task
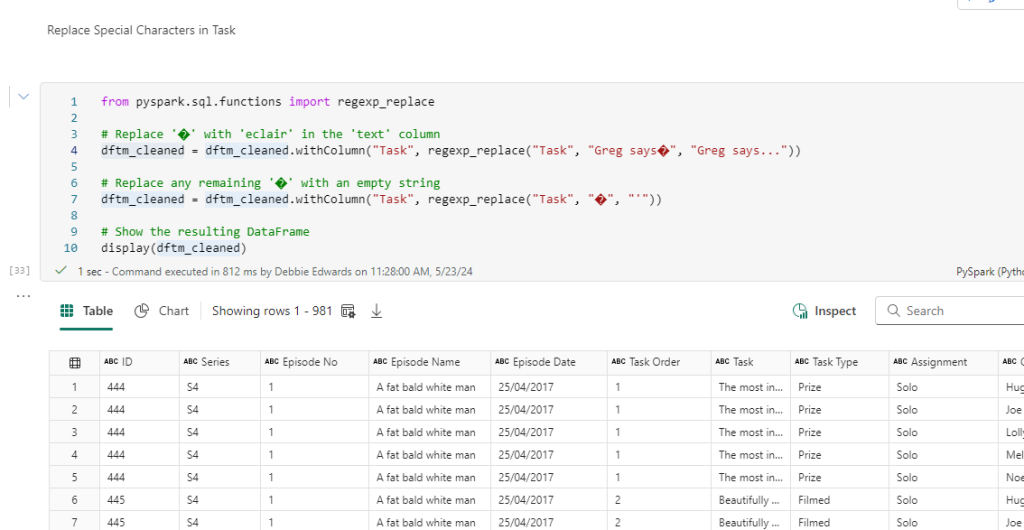

The above was all from Part 5.
Resolve Episode date issues
Currently we have 28/07/2015 and when transforming to date the values are being lost. We need to change the date to 2015-07-28
#Update the date so we can transform it to a date column
from pyspark.sql.functions import col
# Get the Year
dftm_cleaned = dftm_cleaned.withColumn("Year", col("Episode Date").substr(-4, 4))
# Show the resulting DataFrame
dftm_cleaned.show()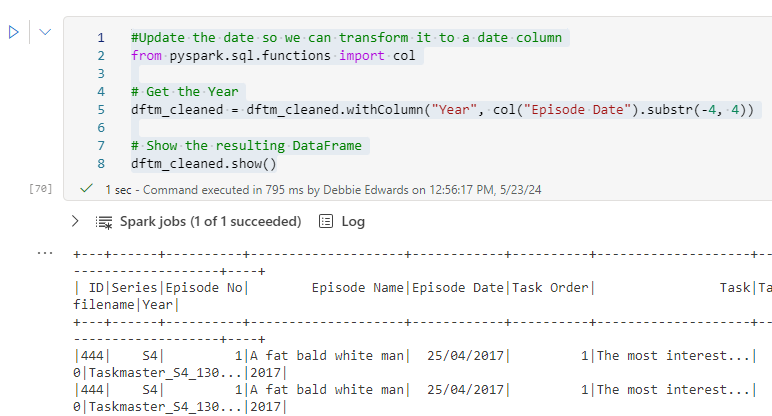
Now add in Day
from pyspark.sql.functions import col, substring
# Assuming you have a DataFrame called 'df' with a column named 'Episode Date'
dftm_cleaned = dftm_cleaned.withColumn("day", substring(col("Episode Date"), 1, 2))
# Show the resulting DataFrame
dftm_cleaned.show()And month
from pyspark.sql.functions import col, substring
# Assuming you have a DataFrame called 'df' with a column named 'Episode Date'
dftm_cleaned = dftm_cleaned.withColumn("month", col("Episode Date").substr(4, 2))
# Show the resulting DataFrame
dftm_cleaned.show()
Merge together and convert to date
from pyspark.sql.functions import concat_ws, col,to_date
# Assuming you have a DataFrame called 'df' with columns 'year', 'month', and 'day'
dftm_cleaned = dftm_cleaned.withColumn("Episode Date", concat_ws("-", col("year"), col("month"), col("day")))
dftm_cleaned = dftm_cleaned.withColumn("Episode Date", to_date("Episode Date", "yyyy-MM-dd"))
# Show the resulting DataFrame
display(dftm_cleaned)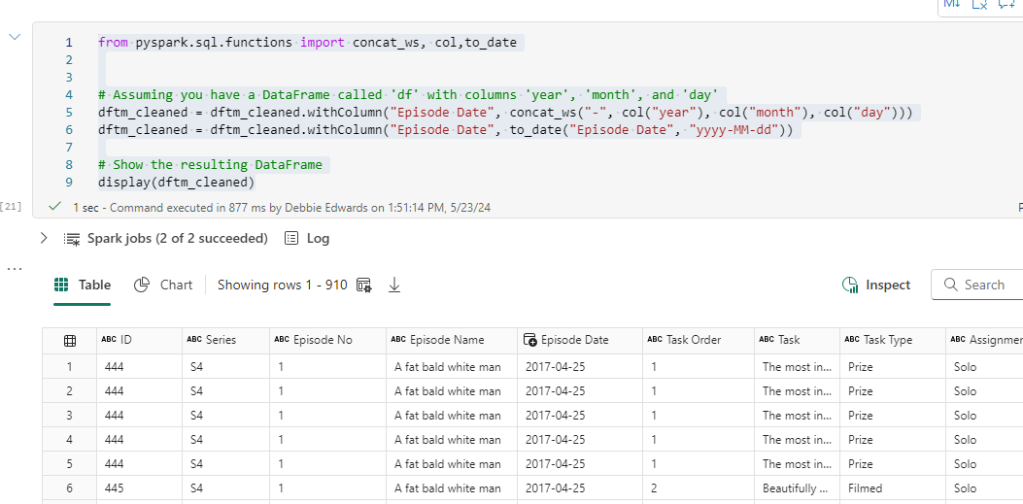
Contestant transformations
we also need to bring through the contestant data which we will join later. This is just one file.
dfc = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/TaskMasterSeriesFiles/Taskmaster/Contestants.csv")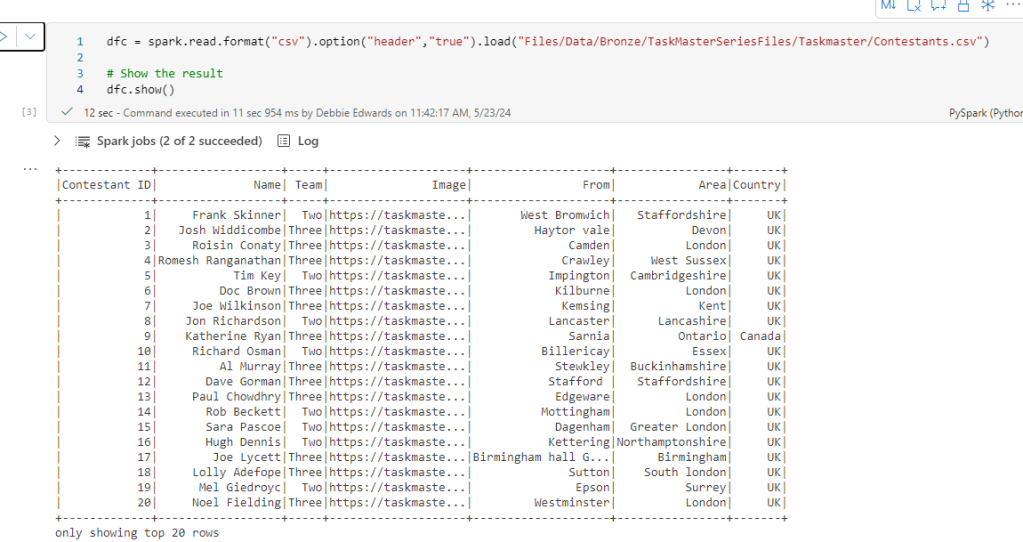
We have our old data set and although we couldn’t turn it into a star schema. there is data that we could use in there to create a more complete data set that can be joined to this data above.
People
#Read the file into a dataframe
dfp = spark.read.format("csv").option("header","true").load("Files/Data/Bronze/people.csv")
#And rename a couple of columns
dfp = dfp.withColumnRenamed("id","contestantID").withColumnRenamed("name","contestant")
display(dfp)
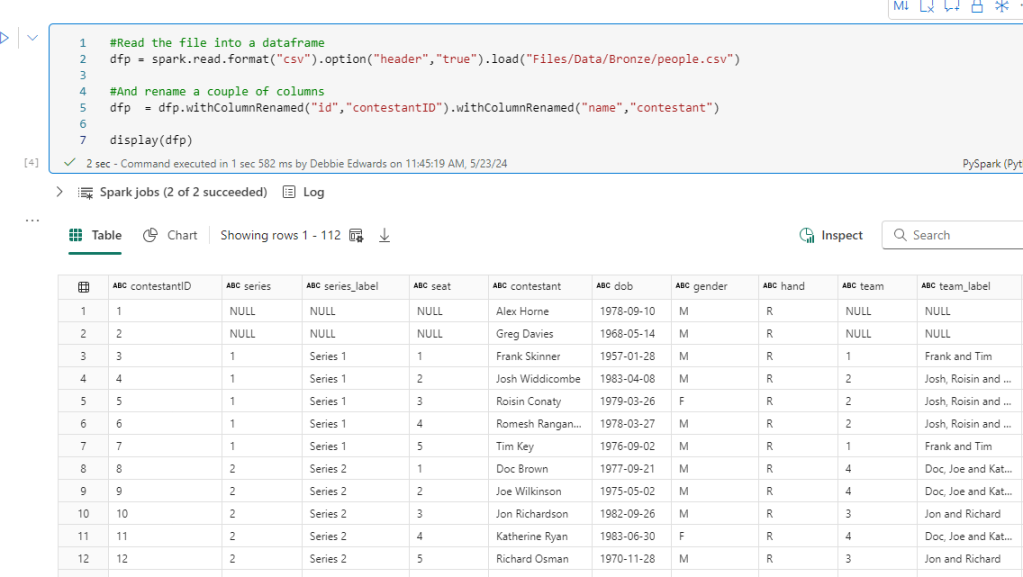
In our original people data We have some great stuff here, Age Hand, Seat. We can use these to create some great Power BI visuals. Lets see if we can merge it into our new data
Join Contestant to people data
# Join the extra contestant information
dfcont = dfc.join(dfp, dfc["Name"] == dfp["contestant"], "left_outer").drop(dfp.contestantID).drop(dfp.series)\
.drop(dfp.series_label).drop(dfp.contestant).drop(dfp.team).drop(dfp.team_label).drop(dfp.champion)\
.drop(dfp.TMI)
# The resulting DataFrame 'joined_df' contains all rows from dftask and matching rows from dfob
display(dfcont )
And lets see if we have any nulls we need to add in.
filtered_df = dfcont.filter(dfcont['seat'].isNull())
display(filtered_df)
Just the one.
Name from new Dataset – Asim Chaudry name from old Data set – Asim Chaudhry
This is completely sortable before the join. The name is incorrect in the new data set so lets insert a code block to update before the join
# Assuming you have already created the DataFrame 'df'
from pyspark.sql.functions import when
# Replace "Asim" with "Ashim" in the 'name' column
dfc = dfc.withColumn("Name", when(dfc["Name"] == "Asim Chaudry", "Asim Chaudhry").otherwise(dfc["Name"]))
dfc.show(1000)
Now we can redo the join and have no null values
Create Age – Create Distinct Min Episode Date
Now this time we want to create the age as at the start of their task master series. Not current age.
So we need to create a new data frame consisting of just the contestant and min Series date
# Assuming you have already created the DataFrame 'dftm_cleaned'
from pyspark.sql.functions import min
# Group by "Contestant" and aggregate the minimum "Episode Date"
dfminSeriesCont = dftm_cleaned.groupBy("Contestant").agg(min("Episode Date").alias("min_episode_date"))
# Show the resulting DataFrame
dfminSeriesCont.show()

Note that we have already transformed the date and set as a date field in the dataframe.
Merge Episode Date with Contestant
Now we need to merge into our contestant file
# Join the min_episode_date into contestants
dfcont = dfcont.join(dfminSeriesCont,dfcont["Name"] == dfminSeriesCont["Contestant"], "left_outer").drop(dfminSeriesCont.Contestant)
# The resulting DataFrame 'joined_df' contains all rows from dftask and matching rows from dfob
display(dfcont)

Add Age
from pyspark.sql.functions import datediff
from pyspark.sql.functions import col
# Convert the date of birth column to a date type in dfCont
dfcont = dfcont.withColumn("dob", dfcont["dob"].cast("date"))
#Calculate age using dob and current date
dfcontAge = dfcont.withColumn("age_decimal", datediff(dfcont["min_episode_date"], dfcont["dob"]) / 365)
#Convert from decimal to int
dfcontAge = dfcontAge.withColumn("age", col("age_decimal").cast("int"))
#Convert Contestant ID to int
dfcontAge = dfcontAge.withColumn("contestant ID", col("contestant ID").cast("int"))
display(dfcontAge)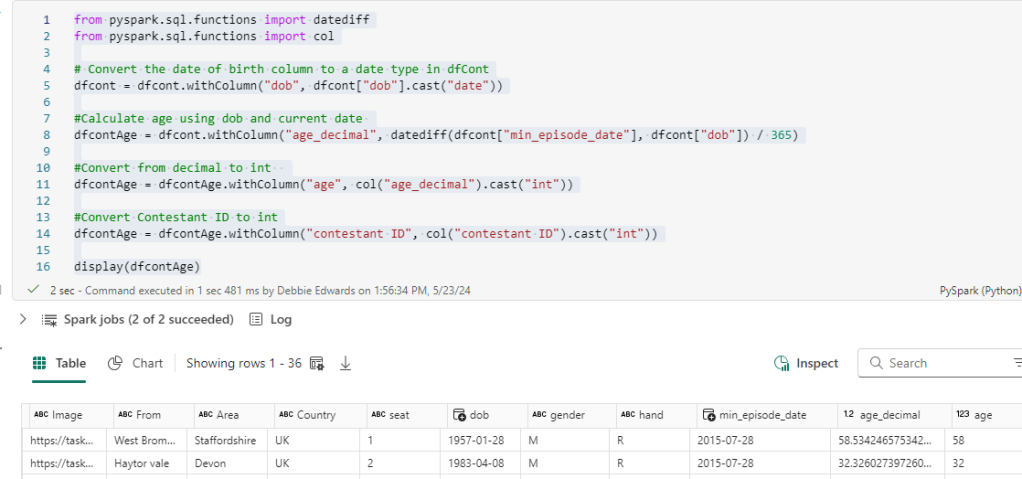
Create an Age Group
from pyspark.sql import SparkSession
from pyspark.sql.functions import when, col
# Apply conditional logic
dfcontAge = dfcontAge.withColumn("ageRange", when(col("age") < 20, "0 to 20")
.when((col("age") >= 20) & (col("age") <= 30), "20 to 30")
.when((col("age") >= 30) & (col("age") <= 40), "30 to 40")
.when((col("age") >= 40) & (col("age") <= 50), "40 to 50")
.when((col("age") >= 50) & (col("age") <= 60), "50 to 60")
.otherwise("Over 60"))
# Show the result
dfcontAge.show()
Save as PARQUET
Save both files as unmanaged PARQUET Files

We don’t need to save as Delta PARQUET because this is the silver layer which will be used to create the Delta PARQUET dim and fact tables.
You can’t directly partition a non-Delta Parquet file, but you can optimize it using V-Order for better performance. V-Ordering is true as default but if you want to check you can always use this code
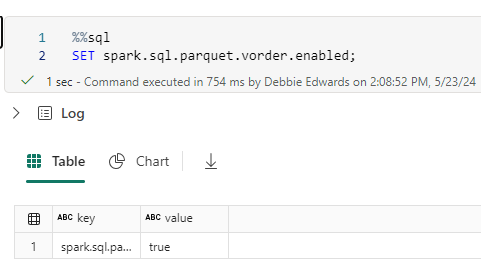
Save your Taskmaster transformed PARQUET Files
Dim Episode
We can now update the original Notebook to use the transformed silver layer data, and remove all the cleaning that’s now in the notebook we have prepared
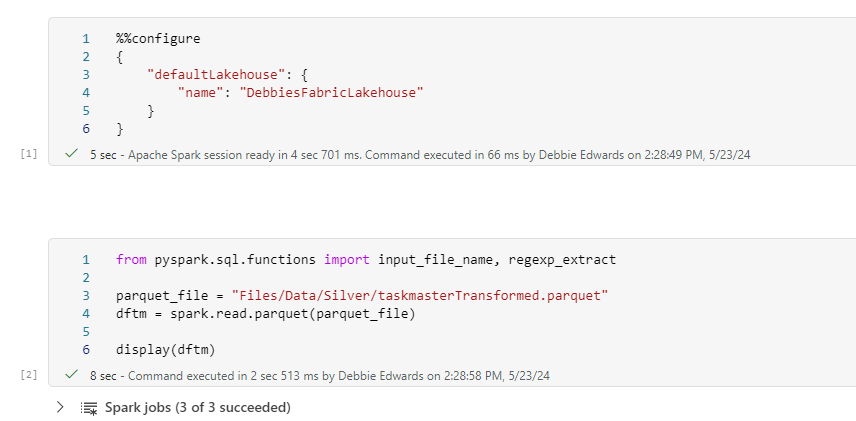
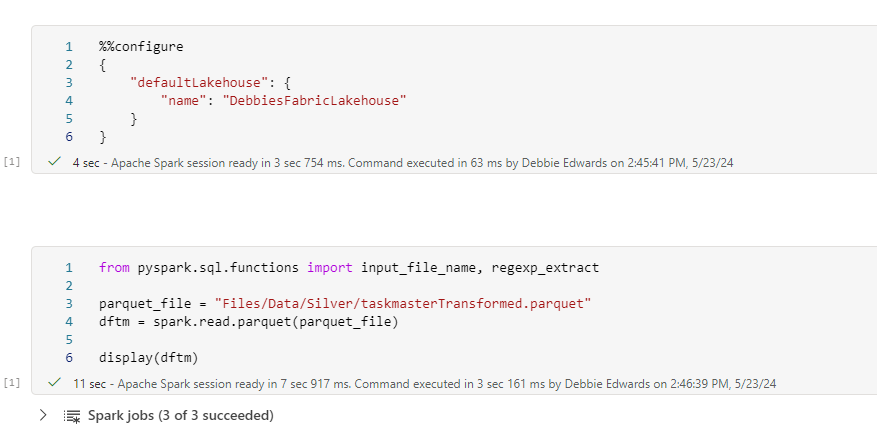
from pyspark.sql.functions import input_file_name, regexp_extract
parquet_file = "Files/Data/Silver/taskmasterTransformed.parquet"
dftm = spark.read.parquet(parquet_file)
display(dftm)Notice the change to the code now we are reading a parquet file.
All the transformation code has been removed and we start at creating the episode Dim
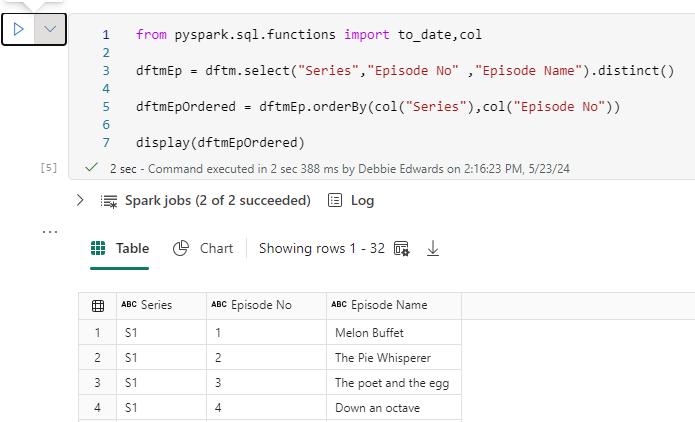
##drop all rows with null values
dftmEp = dftmEp.na.drop(how='all')
display(dftmEp)Create a Default Row
from pyspark.sql import SparkSession
from pyspark.sql import Row
# Create a sample DataFrame
data = [(-1, -1,"Not Known")]
columns = ["series", "episode No", "Episode Name"]
new_row = spark.createDataFrame(data, columns)
# Union the new row with the existing DataFrame
dftmEp = dftmEp.union(new_row)
# Show the updated DataFrame
dftmEp.show(1000)Create an Episode Key
from pyspark.sql.functions import col
from pyspark.sql.window import Window
from pyspark.sql.functions import row_number
# Create a window specification partitioned by "Series" and ordered by "Episode No"
window_spec = Window.orderBy(col("Series"), col("Episode No"))
# Add a new column "EpisodeKey" using row_number() over the specified window
dftmEpKey = dftmEp.withColumn("EpisodeKey", row_number().over(window_spec) - 2)
# Show the result
dftmEpKey.show(1000)Clean the Column Names
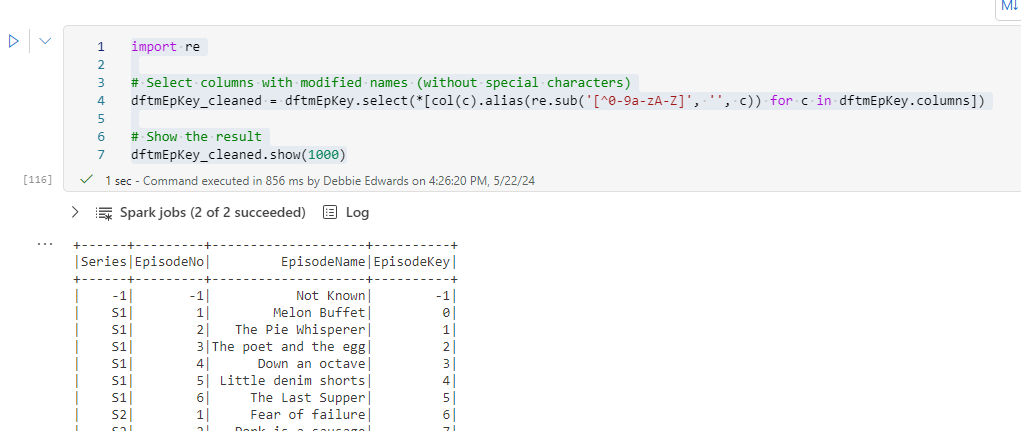
import re
# Select columns with modified names (without special characters)
dftmEpKey_cleaned = dftmEpKey.select(*[col(c).alias(re.sub('[^0-9a-zA-Z]', '', c)) for c in dftmEpKey.columns])
# Show the result
dftmEpKey_cleaned.show(1000)And save to Delta PARQUET and PARQUET (Just to give us the different examples to play with
Dim Task
In this dimension we want the Task, Task Type and Assignment (Solo or Group)
We can hopefully create this quite quickly in a new notebook
Create a new notebook Dim Task V2
The format is completely the same every time
Get the Task fields

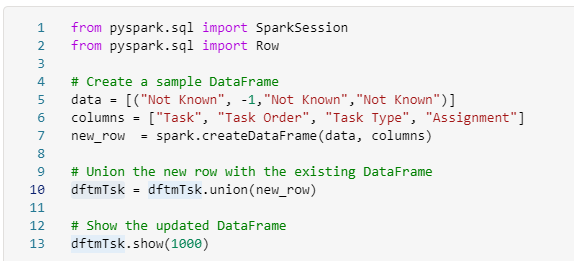
Add a default row
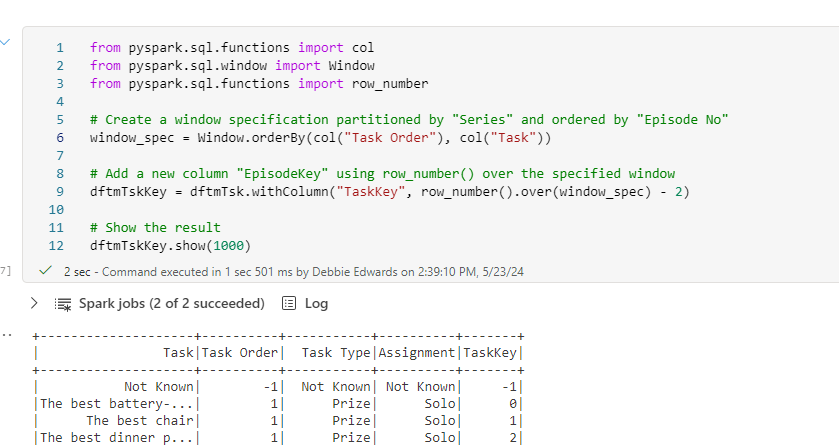
Create the Key
Resolve invalid characters in the column names

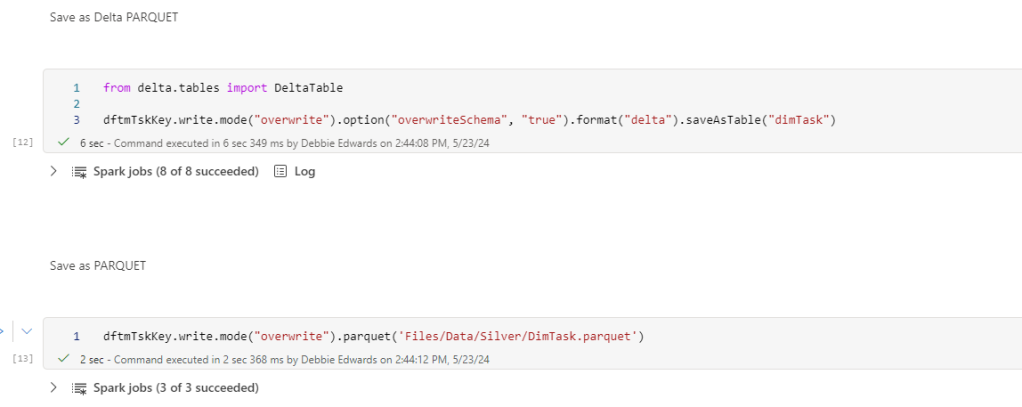
Save as Delta PARQUET and PARQUET
Dim Contestant
We now get to the contestant. Create a new Notebook. Dim Contestant V2
Merge Contestant with the Taskmaster main file
from pyspark.sql.functions import col
# Perform the left join
merged_df = dftm.join(dfc, dftm["Contestant"] == dfc["Name"], "left_outer")\
.select(
dfc["Contestant ID"],
dftm["Contestant"].alias("Contestant Name"),
dftm["Team"],
dfc["Image"],
dfc["From"],
dfc["Area"],
dfc["country"].alias("Country"),
dfc["seat"].alias("Seat"),
dfc["gender"].alias("Gender"),
dfc["hand"].alias("Hand"),
dfc["age"].alias("Age"),
dfc["ageRange"].alias("Age Range"),
).distinct()
# Show the resulting DataFrame
merged_df.show()

In the main file. Teams in only populated when its a group task.
Therefore we are getting two records. one with and one without a team so we need to remove rows
dfContfinal = merged_df.dropna(subset=["Team"])
# Show the resulting DataFrame
dfContfinal.show(1000)Add a Default Row

Create a Contestant Key
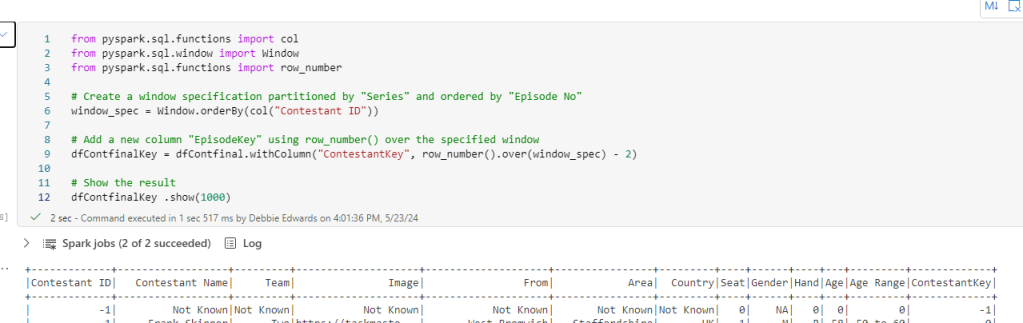
Clean Column Names

Alias Column Names
renaming all columns to get past the issues with special characters in columns

Save as Delta PARQUET and PARQUET
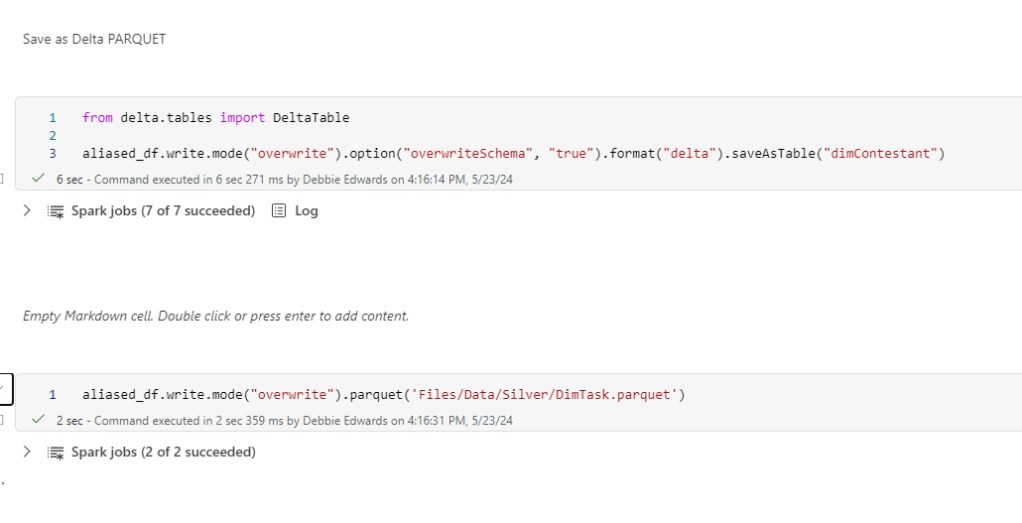
Save the File and ensure you have committed source control
At the end of this post, we have all our dimensions (Date was created in a previous blog).
Next post will be creating the central fact table
And better yet, we have had more of a chance to convert all our year of SQL knowledge across to pyspark.