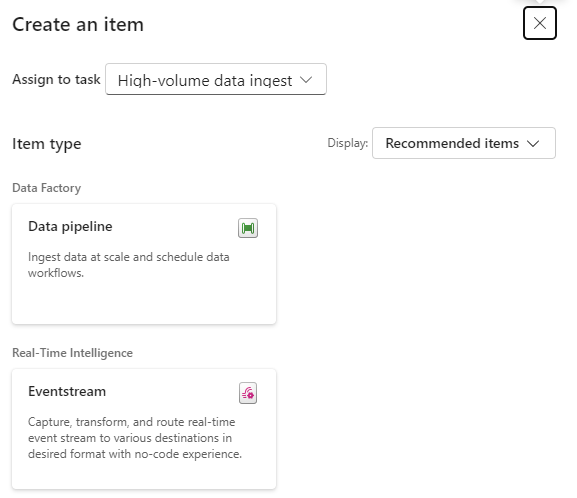
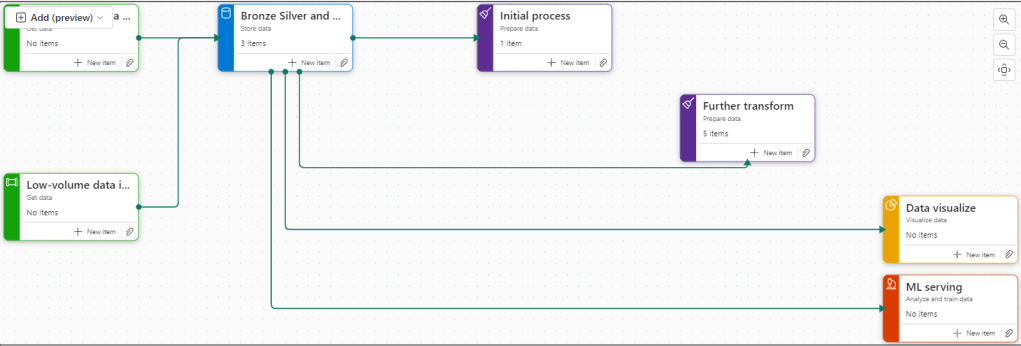
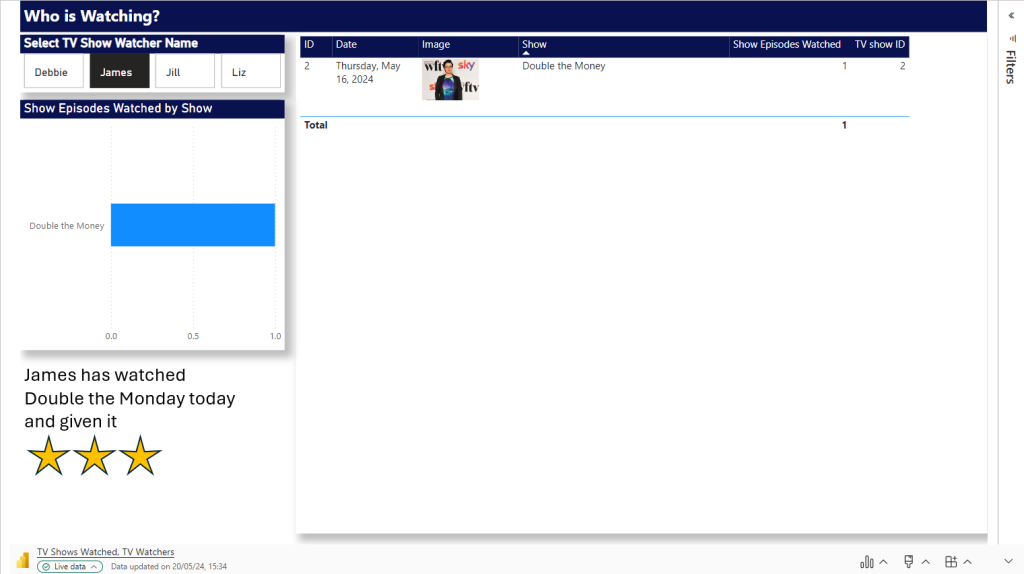
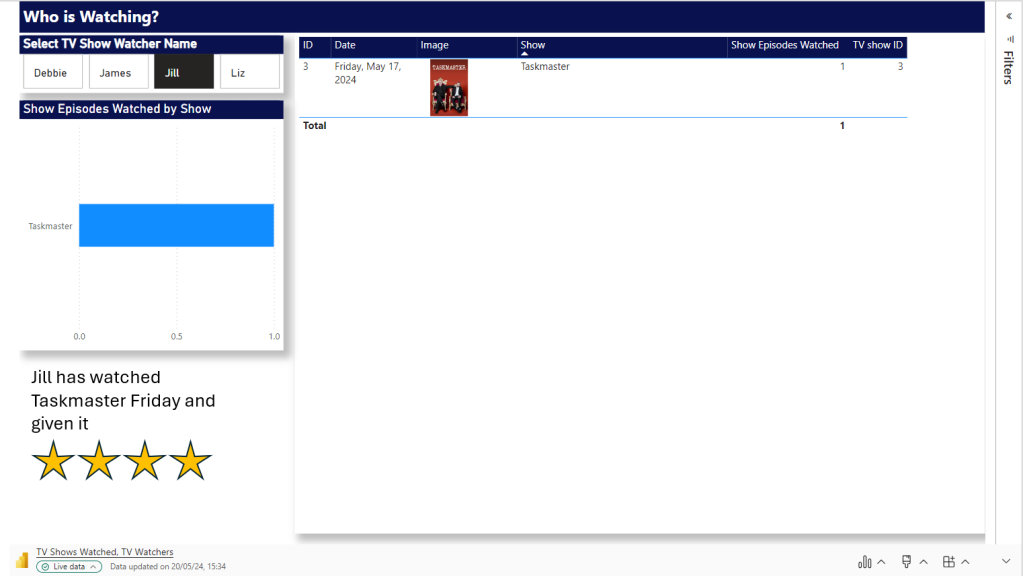
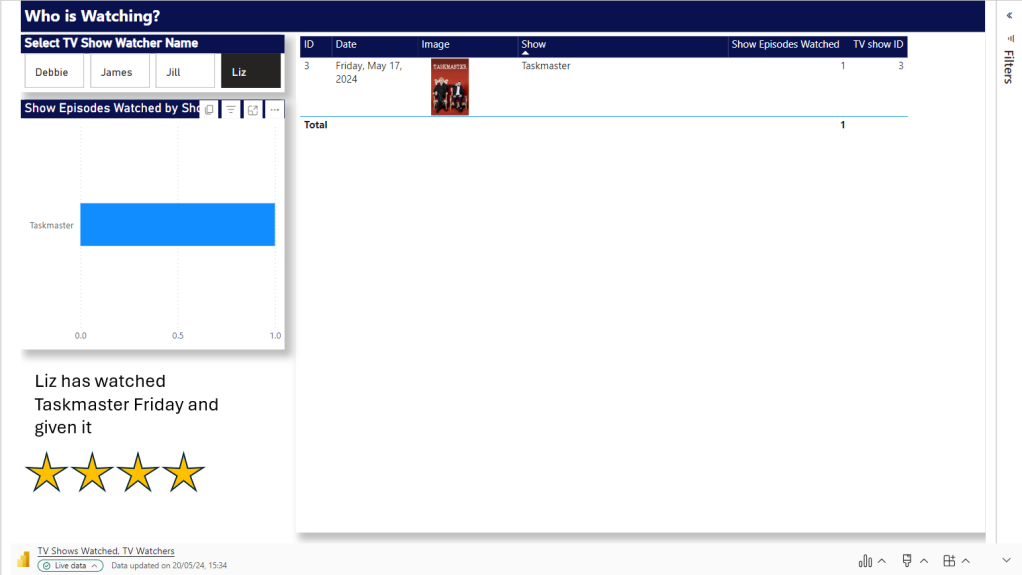
In part 1 of our initial lessons learned in Fabric blog, we looked at Data Engineering components. Our transformed dimensions and fact tables are now stored in Delta Parquet format within the Fabric Gold Lakehouse.
Now its time to look at what we can do with the Power BI Fabric functionality. Lets build our Semantic model and Reports.
The Semantic Model
Previously, the semantic model was created in Power BI Desktop. We could then create another desktop file and connect to the semantic model that had been published to the power BI Service.
With Fabric. You create the semantic model in the Fabric workspace.
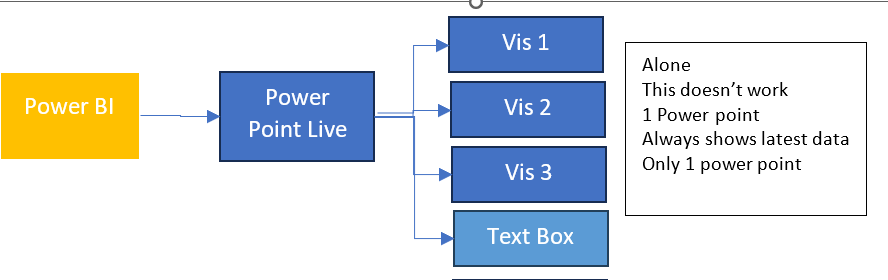
We are going to use Direct Lake connection to the Delta Parquet files. As a consequence we don’t need to create dataflows. Lets look at how this looked previously.

Without the SQL DB, with Power BI Premium. Data flows can get complex, as usually the transformations happen within the SQL database. Here they are used to simply store the data centrally before being imported into the semantic model.
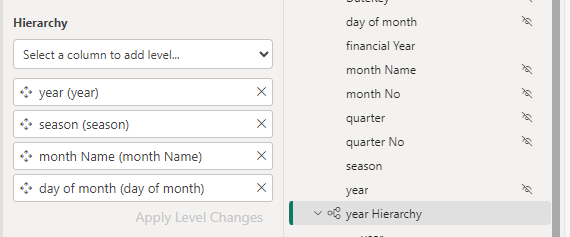
You can use the data flows in multiple semantic models. For example, your date dimension could be reused in many models.
Now, we are looking at the following logic.
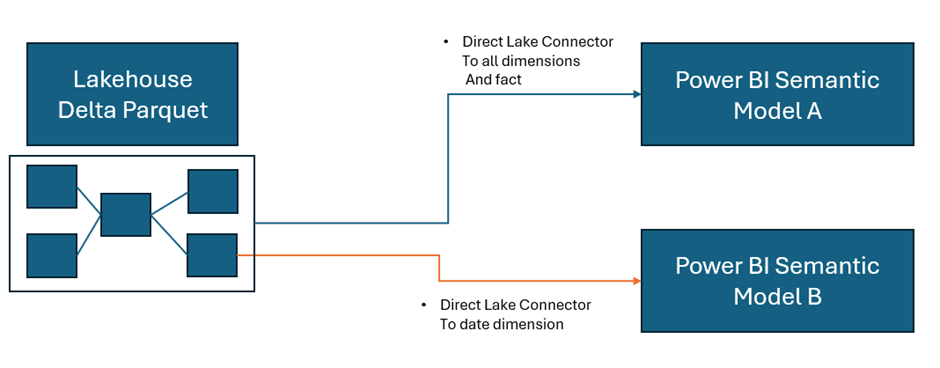
As a consequence, this project has been simplified to Delta Parquet and Semantic model.
In the Lakehouse, go to SQL analytics endpoint


At the bottom of the screen we have a model view. This is the Default Model view

This takes us to the Semantic Model. However, when trying to update the default model we get hit with errors

After looking at some of these issues online, it would appear that currently the ‘default’ semantic model is quite glitchy and many people are having issues with it.
People are using work arounds by creating their own semantic models rather than using the default semantic model. So currently, the default is left alone and a new semantic model is created.
Back in the Lakehouse

Choose New Semantic Model

And work in the same way as you would within your Power BI desktop file. Note that we don’t have to publish. The model auto saves.

And you can then commit your model changes to your GIT repository. Eventually creating versions of your model. You can quickly create a new report in Fabric to check your DAX as you go. This is a real change from how we used to work. Where the power BI PBIX file was simply a black box file, with no opportunities to store the code in GIT.
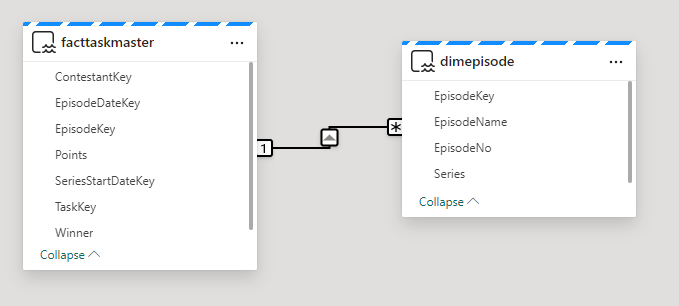
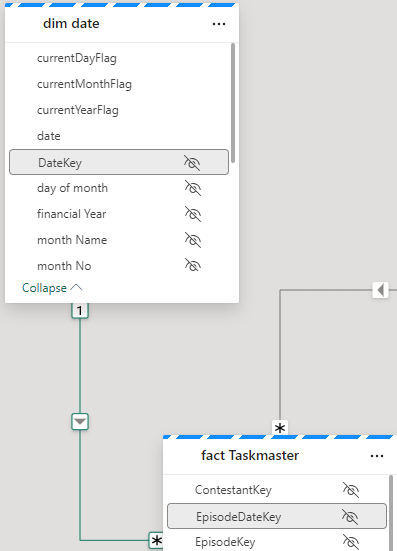
Notice the connections on each object

Direct Lake. Power BI directly connects to the Delta Parquet file. Just like Power BI, the file is a columnar data store, and we do not lose any DAX functionality.
Power BI Reporting
As we have seen. You can create reports directly in Fabric. A big question is, is Power BI desktop still the best thing to use?
Again I think the answer to this question is definitely yes. Although the Fabric reports can be good for quick data model testing.
- Desktop allows for Offline development
- Power BI Desktop can be more responsive that working on the cloud
- Power BI reporting allows for better version control. You can save locally and publish to the service when ready.
- Desktop integration with other external tools and services
- Desktop provides more options and flexibility that reporting within Fabric.
With this in mind. Another update we can take advantage of is the Power BI PBIP (Project) desktop files. PBIP allows for version control and collaboration. Finally, Our Power BI files are broken up and code can be stored in out GIT repositories.
PBIP (the Power BI Project File)
Get Data
In Power BI Desktop you can access your Power BI semantic models

Create reports from the Semantic model(s) in Fabric.
Create the Power BI Project (PBIP)
Instead of simply saving as a pbix (black box) file, Save as a project file and see how this can really change how you work. We should see benefits like:
- Items are stored in JSON format instead of being unreadable in one file
- JSON text files are readable and contain the semantic model and report meta data
- Source Control. Finally real source control for Power BI
- Amendable by more than one person at a time
- The possibility of using (CI/CD) Continuous Integration and Continuous Delivery with Power BI
Saving as a project is (Currently) in preview so lets turn it on.
Options and Settings / Options

And now we can Save as report.pbip

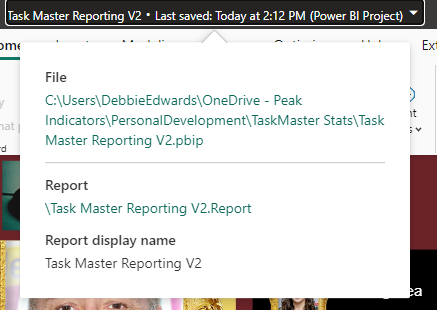
After saving, the project is stated in the title. Lets have a look at what has been created in Explorer

The main project file

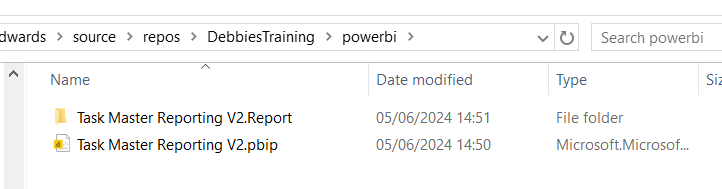
The reporting folder

The objects within the reporting folder.
For the initial test. The pbip was save to One Drive. It needs to get added into Devops so it can be added into the full source control process along with all the Fabric code.
Azure DevOps: build pipelines for continuous integration
Ensure Fabric is already connected to Azure Devops And cloned to a local drive.
Add a powerbi folder in the local repository and all the Power BI Objects are moved here.

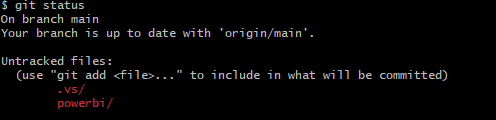
PBIP is in local but not yet in the cloud.
Git Bash is installed locally to work with https://git-scm.com/downloads
Using GIT Bash you can push the powerBI files up to the central repository by creating a new branch to work on

Add and commit the changes. Then Push to the cloud
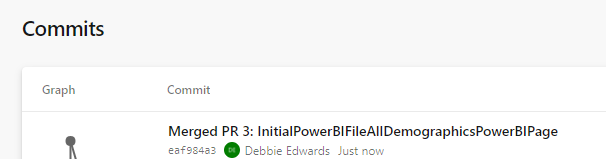
Back in DevOps

We can see the Power BI Items. If you have pushed to a branch, you can then create a pull request to pull the new power BI files over into main.
To work with the file again, remember to open the (PBIP) project file from your local repository. Then you can work in Git Bash to once again. Create a new branch. Add, Commit and Push the changes.
For self service Power BI developers, this may be something that takes time to embed itself, since the process is more complex and you need to have some understanding of version control but it is really worthwhile to train your developers and build this into your standard procedures. Especially with the Silver and Gold standard (Promoted and Certified) content.
The Fabric Capacity Metrics App
Finally, lets take a quick look at the Fabric Capacity Metrics app. You need to be an admin to install and view the report.
Why is the Fabric capacity app important?
- It provides insights into how the capacity is being used.
- Monitoring usage patterns helps to identify how to scale resources up and down.
- High usage items can be quickly identified
Installing the App
Go into your Fabric Workspace and click on the settings cog at the top right of the screen and select the governance and insights Admin Portal

I am the admin for the Fabric capacity so ensure you know who your Fabric Capacity Admin is
Click on the capacity and get the capacity ID from the URL

You can use the ID for the Capacity Metric App
In the Fabric Workspace. Go to your Power BI experience at the bottom left of the screen

Click on Apps and Get Apps

Search for the Fabric capacity App and Get it Now to install

Connect to start working with the app
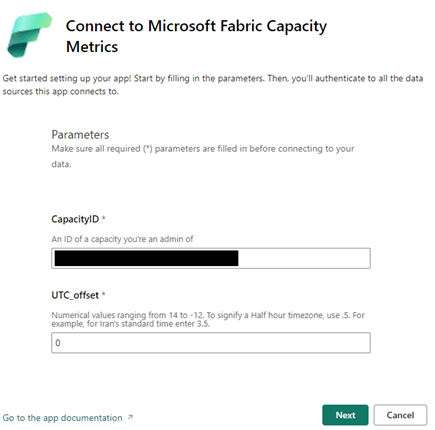
The screen is where you can use the capacity ID, copied from the Admin Portal. You then need to sign in and connect.

Here is where the Fabric experience falls down for me slightly currently.
The capacity app doesn’t show financial costs (Although part of the license fee. There are still costs to running spark jobs). Also, only the Fabric admin can see this information.
As a none admin user, I still want the power to be able to see my utilisation as I work with fabric.
Conclusion
The more you learn with Fabric the more exciting it gets. The next goals are to work with the Data Warehouse and the real time capabilities.
There are so many opportunities to use the Delta Lake or SQL DW as our transformation (Staging area) with Direct Lake Power BI connection. I can see Delta Lake being the option of choice to quickly to build up smaller solution projects.
As a SQL Developer, I am now a big fan of Pyspark. These two make a great tool set for the Fabric analytics engineer.
And as always with Power BI, there are exciting updates every month to look forward too. You never stop learning as an Analytics Engineer.
As at time of adding this blog. I am working towards the Fabric Engineer Certification after getting my Azure Engineer Associate some time ago. So lots more to think about. My current excitement is the real time analytics within Fabric. I.m really looking forward to trying to implement a project with this.