
A current project has an xlsx containing around 40 lookups in individual worksheets
Each worksheet consists of a code and a description
We decide that we want every single lookup in one lookups table in SQL Server.
This will have a Lookup Name, Code and Description that we can then use for the rest of the project
We want to do everything in one go in Data Factory.
For this Im going to use a simple example with just 3 worksheets
Azure Data Lake Gen 2
We are going to store the source data within a data lake.
The Source data looks like this

Lookup B worksheet

Lookup C Worksheet

SQL Server
I have an Azure SQL Database and on it I create the one table that all the reference lookups will go into
GO
CREATE TABLE [staging].[Lookups](
[LabelKey] [int] IDENTITY(1,1) NOT NULL,
[LabelName] varchar NULL,
[Code] [int] NULL,
[LabelDescr] varchar NULL,
[Importdate] [datetime] NULL
) ON [PRIMARY]
GO
ALTER TABLE [staging].[Lookups] ADD DEFAULT (getdate()) FOR [Importdate]
GO
LabelKey has been added just to create a valid key for the table. LabelName has also been added which will be the name of the worksheet.
Finally ImportDate is added because we want to know exactly what time this data was imported into the table
Now we need to provide Data Factory with a list of worksheets
CREATE TABLE [staging].[LookupNames](
[LabelKey] [int] IDENTITY(1,1) NOT NULL,
[Labels] varchar NULL,
[Importdate] [datetime] NULL
) ON [PRIMARY]
GO
ALTER TABLE [staging].[LookupNames] ADD DEFAULT (getdate()) FOR [Importdate]
GO
Lookup Names is our seed table and will provide us with the worksheet names
we have populated it like this
SELECT 'Lookup A' UNION
SELECT 'Lookup B' UNION
SELECT 'Lookup C'
Data Factory
Linked Services
Firstly we need to provide our linked services. Source and destination
go to Linked services via

and choose new.

call it ADLS_LS and select your Azure Subscription and Storage account.
At this point the connection was tested and was successful so we didn’t need to do anything further
Next, create your Azure SQL Database Linked Service

And call is SQLDB_LS (Or what ever you feel is the right naming convention. _LS is good because you can see exactly what are the linked services in the JSON script created
Again add in your details (We used a role that we created in SQL Server DB specifically for data factory with GRANT EXEC, SELECT, INSERT, UPDATE, DELETE on all the schemas)
Ensure the connection is successful
Data Sets
Now to come up with the actual source and destination datasets. If we parameterise them then we can reuse a single data set for lots of other activities within the pipeline


Click on the … and choose New dataset

Choose the Format. In this case its Excel



We don’t want to specify any of the location values until we get to the pipeline, including the worksheet
Make sure First row as header is ticked (Unless you don’t have a header in Excel)

And create parameters


This means we can use this one Data set for all the SQL data sources
Pipelines
Now to create the pipeline specifically for the lookup

This is the basic pipeline we are going to add.
Lookup
First of all In Activities search for lookup and drag this into the pane

This uses the SQL dataset because we are going to use our SQL table that contains all the names of the worksheets.
Note that first row only is not ticked because we are bringing all the information through
ForEach


@activity(‘GetLookups’).output.Value
We are going to get the entire data set (Value) fed into the GetLookups Lookup.
Sequential is ticked because we are going to move through all the worksheets names in the table (Ensure that your Worksheets have exactly the same name as what is specified in your table)
Click on the Activities (1) to get to the activity
Copy Activity within the Foreach

We now set up the source of the copy activity

We use all the parameters within the dataset and add in the information from our Azure data Lake Gen 2 in the Storage Resource.

Within our Lookups table there is a column called labelname and we are going to populate this with the Labels column from our item. Out Item in the foreach loop and was created via the Lookup. And that lookup contained all the columns from our LookupNames SQL Table

The data will go into the Lookups table
Thats everything. You should be able to test your Pipeline by clicking debug and the Foreach should move through worksheet specified within your lookupnames table and add your information into SQL


Truncating lookup tables before re adding data
we want to be able to repeat this process and unless we add a truncate statement into our process we will keep readding the same information
We can add the following Stored procedure into SQL
/* 05/10/2020 Debbie Edwards - Peak - Truncate lookups EXEC [staging].[USP_Truncatelookups] */
Create PROCEDURE [staging].[USP_Truncatelookups]
AS
BEGIN
IF EXISTS(SELECT * FROM [dbo].[sysobjects] WHERE Name = 'lookups')
TRUNCATE TABLE [staging].[Lookups]
DBCC CHECKIDENT ('Staging.Lookups', RESEED, 1)
END
And this can be added to the the Pipeline before the foreach loop and Lookup with a Stored Procedure Activity
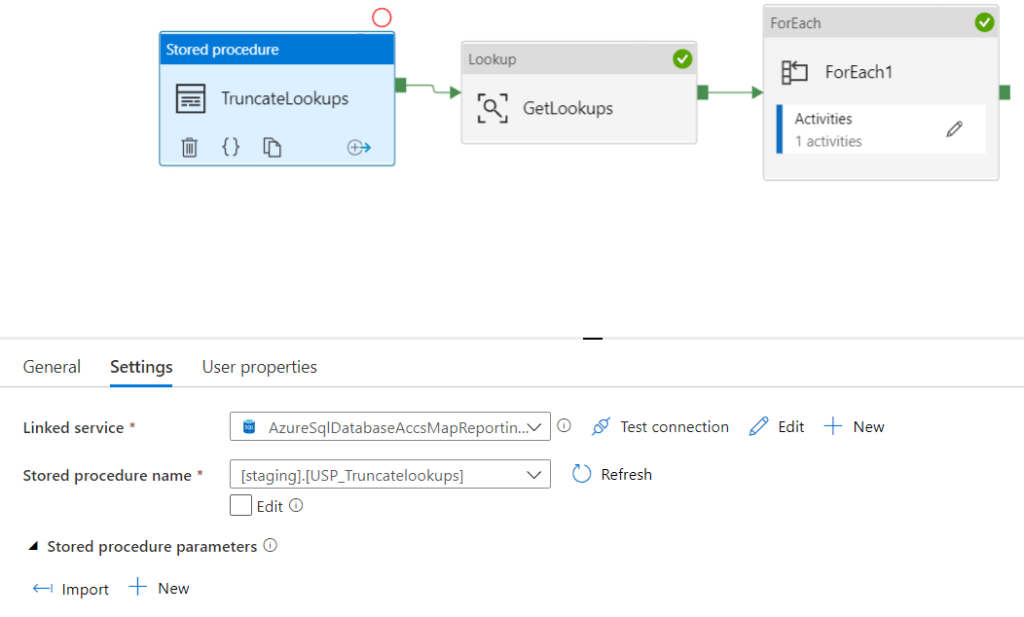
You wont be able to see the Stored procedure if you havent granted EXEC access to the specific Database Role name and schema
Always give the least amount of privileges and them move up if you need to
--Bring back information about the members in your roles
SELECT DP1.name AS DatabaseRoleName,
isnull (DP2.name, 'No members') AS DatabaseUserName
FROM sys.database_role_members AS DRM
RIGHT OUTER JOIN sys.database_principals AS DP1
ON DRM.role_principal_id = DP1.principal_id
LEFT OUTER JOIN sys.database_principals AS DP2
ON DRM.member_principal_id = DP2.principal_id
WHERE DP1.type = 'R'
ORDER BY DP1.name;
SELECT DISTINCT rp.name,
ObjectType = rp.type_desc,
PermissionType = pm.class_desc,
pm.permission_name,
pm.state_desc,
ObjectType = CASE
WHEN obj.type_desc IS NULL
OR obj.type_desc = 'SYSTEM_TABLE' THEN
pm.class_desc
ELSE obj.type_desc
END,
s.Name as SchemaName,
[ObjectName] = Isnull(ss.name, Object_name(pm.major_id))
FROM sys.database_principals rp
INNER JOIN sys.database_permissions pm
ON pm.grantee_principal_id = rp.principal_id
LEFT JOIN sys.schemas ss
ON pm.major_id = ss.schema_id
LEFT JOIN sys.objects obj
ON pm.[major_id] = obj.[object_id]
LEFT JOIN sys.schemas s
ON s.schema_id = obj.schema_id
WHERE rp.type_desc = 'DATABASE_ROLE'
AND pm.class_desc <> 'DATABASE'
AND rp.name = 'db_NameofRole'
you should hopefully have a good pipeline to run in your lookup information into one lookup table and truncate that table when ever you run the process









