
In Azure Data Factory Moving from development and Production We looked at how we can use Azure DevOps to move the Json Code for Development Data Factory from development to Production.
Its going well, I have however been left with an issue. every time I move into Production details for the Linked Services have to be re added. Lets have a look at the SQL Server and the Data Lake gen 2 account.
Development

Notice that the information has been entered manually including the Storage account Key.

Again, in this instance the information has been entered manually. SQL Server Authentication is being used because we have a user in the SQL DB with all the privileges that Data Factory Needs.
DevOps Data Factory release Pipeline
Go into Edit of the Release Pipeline
Within Prod Stage we have an Agent Process

We are looking for the Section Override Template Parameters
- -factoryName “prd-uks-Project-adf”
- -AzureDataLakeStorageGen2_LS_accountKey “”
- -AzureSqlDatabaseTPRS_LS_connectionString “”
- -AzureDataLakeStorageGen2_LS_properties_typeProperties_url “https://prduksProjectsa.dfs.core.windows.net/”
- -AzureKeyVault1_properties_typeProperties_baseUrl “https://prd-uks-Project-kv.vault.azure.net/”
Note that currently Account Key and SQL Database Connection String are null.
Provisioning Azure Key vault to hold the Secrets
Managed Identity for Data Factory
Copy your Azure Data Factory Name from Data Factory in Azure
You need to have a Key vault set up in Development

GET and LIST allows Data Factory to get information from the Key Vault for secrets
Paste the data factory name into Select Principal

Key Vault, create a Secret for the Azure Data Lake Storage


For the Key Vault Secret. I gave it the Secret value by copying across the Access Key from the Azure Storage Account Keys Section
The Content type was simply set as the name of the Storage Account for this excercise
In Data Factory Create a Linked Service to the Key Vault

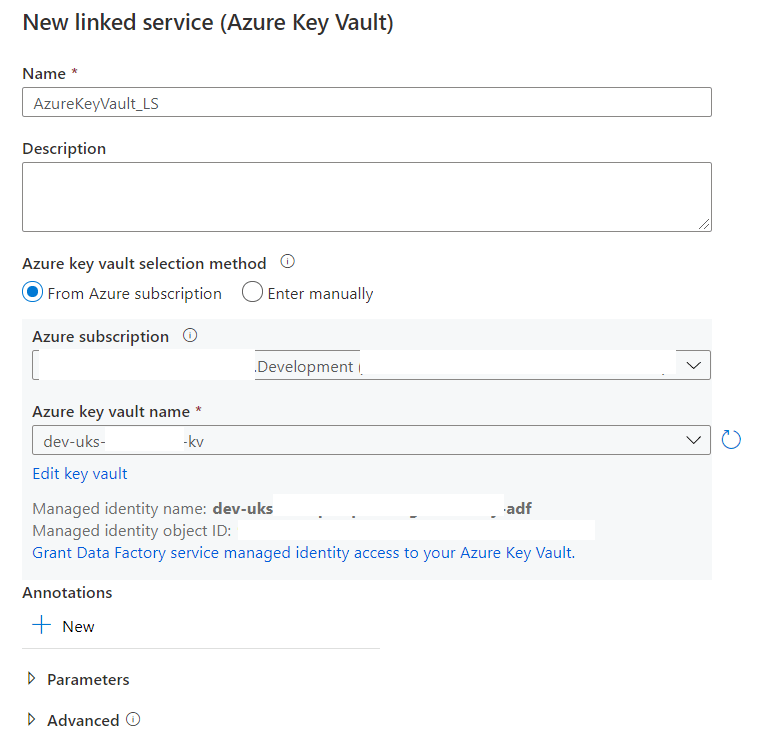
Test and ensure it successfully connects

Use the New Key Vault to reset the data Lake Linked Service

How does this Data Lake Linked Service change the DevOps Release Pipeline?
Its time to release our new Data factory settings into Production. Make sure you have Published Data Factory into Devops Git.

Production Key vault Updates
We need to update Production in the same way as Development
- In Production Key vault add the Production data factory name to Access Policies (as an Application) With Get and List on the Secret
- Ensure that there is a Secret for the Production Data Lake Key AzureDataLakeStorageGen2_LS_accountKey
- Check your Key vault connection works in Production before the next step
Azure DevOps Repos
In Azure Devops go to your Data Factory Repos



Notice that your Linked Service information for the Data Lake now mentions the Key Vault Secret. its not hardcoded anymore which is exactly what we want
Azure DevOps Release Pipeline
Go to Edit in the Data Factory release pipeline

When the job in Prod is clicked on, you can go to the Override Parameters Section. And notice there is now an error

AzureKeyVault1_properties_typeProperties_baseUrl is the missing Parameter. Basically at this point you need to delete the code in the Override template Parameters box and then click the button to regenerate the new parameters
Override with production information (I saved the code so I could re copy the bits I need.
Once done, notice that the -AzureDataLakeStorageGen2_LS_accountKey “” parameter is now gone because its being handled by the key vault.

Lets Save and Create a Release

New failures in the Release

2021-02-08T13:45:13.7321486Z ##[error]ResourceNotFound: The Resource ‘Microsoft.DataFactory/factories/prod-uks-Project-adf’ under resource group ‘prd-uks-Project-rg’ was not found. For more details please go to https://aka.ms/ARMResourceNotFoundFix
Make sure that your override parameters are ok. I updated:
- Data Factory name from Data Factory
- Primary endpoint data Lake Storage from Properties
- Vault URI from Key vault Properties

Repeat the Process for SQL Database
With everything in place we need to introduce a connection string into Key Vault
I have a user set up in my SQL database. the user has GRANT SELECT, INSERT, UPDATE, DELETE, EXEC, ALTER on all Schemas
I want to include the user name and password in the Connection string and use SQL authentication
Secret Name
AzureSQLDatabase-project-ConnectionString
Secret
Server=tcp:dev-uks-project-sql.database.windows.net,1433; Database= dev-uks-project-sqldb; User Id= projectDBowner;Password= Password1;
the connection string has been set as above. For more information on connection strings see SQL Server connection Strings
Go back to Data factory and set up the new secret for SQL Server

This is successful
Data Factory and DevOps
- back in Data Factory Publish the new linked Service Code
- go into Dev Repos and check in Linked Service code you are happy with the new Key vault information
- Go to Prod Key vault and make sure you are the Secret is set with the Connection String for SQL DB
- Test the Key vault secret works in Prod
- Back in DevOps Go to Release pipelines and Edit for the adf Release CD pipeline (Release Pipelines are Continuous Delivery. Build pipelines are CI for Continuous Integration)
- Edit Prod Stage (I only have Prod) Arm Template Deployment Task, Copy Overwrite Template Parameters code into a file for later
- Delete the code and click the … to get the latest parameter information
- Re add your production parameters, most can be taken from the code you just copied.
- Create a new Release
- go to Linked Services in Data Factory and check they are still Production. They still use Key vault and they still work
Now this is all in place, Development Data factory can be published up to production. there is no need to reset Linked Services and all your information about Keys and passwords are hidden in the Key Vault







































